
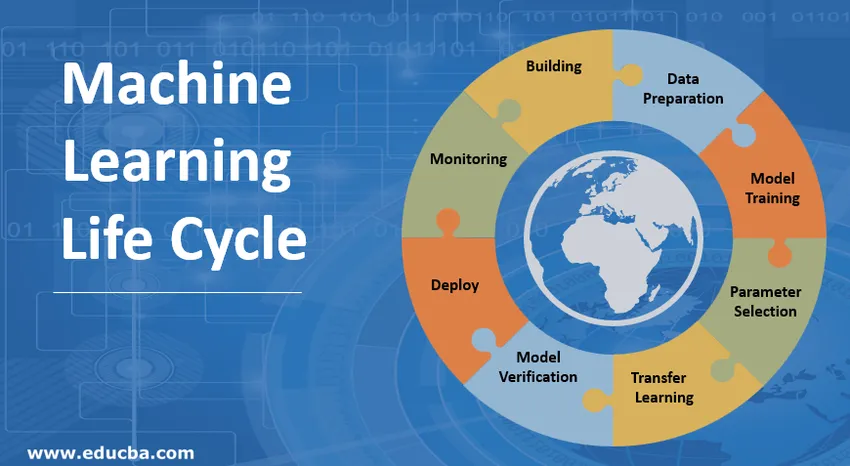
Wprowadzenie do cyklu życia uczenia maszynowego (ML)
Cykl życia uczenia maszynowego polega na zdobywaniu wiedzy za pomocą danych. Cykl życia uczenia maszynowego opisuje trójfazowy proces wykorzystywany przez naukowców i inżynierów danych do opracowywania, szkolenia i obsługi modeli. Opracowywanie, szkolenie i serwis modeli uczenia maszynowego jest wynikiem procesu zwanego cyklem życia uczenia maszynowego. Jest to system, który wykorzystuje dane jako dane wejściowe, mając zdolność uczenia się i ulepszania korzystania z algorytmów bez konieczności programowania. Cykl życia uczenia maszynowego składa się z trzech etapów, jak pokazano na poniższym rysunku: opracowanie potoku, szkolenie i wnioskowanie.
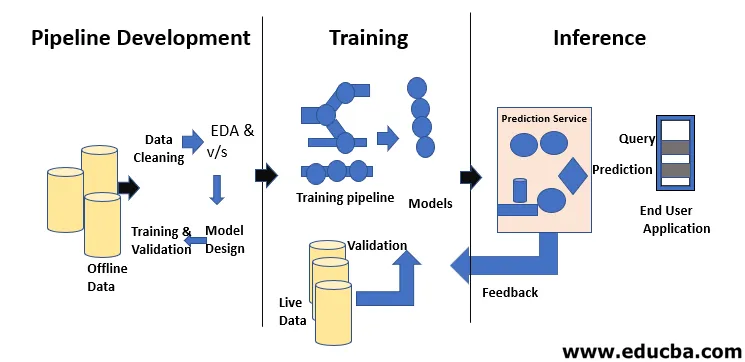
Pierwszym krokiem w cyklu życia uczenia maszynowego jest przekształcenie surowych danych w oczyszczony zestaw danych, który to zestaw danych jest często udostępniany i ponownie wykorzystywany. Jeśli analityk lub analityk danych, który napotka problemy w otrzymanych danych, muszą uzyskać dostęp do oryginalnych danych i skryptów transformacji. Istnieje wiele powodów, dla których możemy chcieć wrócić do wcześniejszych wersji naszych modeli i danych. Na przykład znalezienie wcześniejszej najlepszej wersji może wymagać przeszukiwania wielu alternatywnych wersji, ponieważ modele nieuchronnie obniżają swoją moc predykcyjną. Istnieje wiele przyczyn tej degradacji, takich jak zmiana w dystrybucji danych, która może spowodować gwałtowny spadek mocy predykcyjnej jako kompensacji błędów. Diagnozowanie tego spadku może wymagać porównania danych szkoleniowych z danymi na żywo, ponownego przeszkolenia modelu, przeglądu wcześniejszych decyzji projektowych, a nawet przeprojektowania modelu.
Uczenie się na błędach
Opracowanie modeli wymaga oddzielnych zestawów danych szkoleniowych i testowych. Nadużywanie danych testowych podczas szkolenia może prowadzić do słabej uogólnienia i wydajności, ponieważ może to prowadzić do nadmiernego dopasowania. Kontekst odgrywa tutaj istotną rolę, dlatego konieczne jest zrozumienie, które dane wykorzystano do szkolenia zamierzonych modeli i z jakimi konfiguracjami. Cykl życia uczenia maszynowego jest oparty na danych, ponieważ model i wyniki szkolenia są powiązane z danymi, na których zostały przeszkolone. Przegląd całego procesu uczenia maszynowego z punktu widzenia danych pokazano na poniższym rysunku:
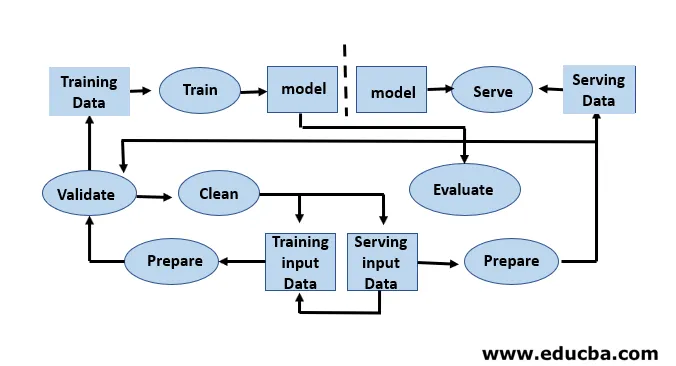
Kroki zaangażowane w cykl uczenia się maszynowego
Programista Machine Learning stale przeprowadza eksperymenty z nowymi zestawami danych, modelami, bibliotekami oprogramowania, dostrajaniem parametrów w celu optymalizacji i zwiększenia dokładności modelu. Ponieważ wydajność modelu zależy całkowicie od danych wejściowych i procesu szkolenia.
1. Budowanie modelu uczenia maszynowego
Ten krok decyduje o typie modelu na podstawie aplikacji. Okazuje się również, że zastosowanie modelu na etapie uczenia się modelu, dzięki czemu można je odpowiednio zaprojektować zgodnie z potrzebą zamierzonej aplikacji. Dostępnych jest wiele modeli uczenia maszynowego, takich jak model nadzorowany, model nienadzorowany, modele klasyfikacyjne, modele regresji, modele grupowania i modele uczenia wzmacniającego. Dokładny wgląd pokazano na poniższym rysunku:
2. Przygotowanie danych
Do celów uczenia maszynowego można wykorzystać różnorodne dane. Dane te mogą pochodzić z wielu źródeł, takich jak firma, firmy farmaceutyczne, urządzenia IoT, przedsiębiorstwa, banki, szpitale itp. Duże ilości danych są dostarczane na etapie uczenia się maszyny, ponieważ wraz ze wzrostem liczby danych dostosowuje się do przynosząc pożądane wyniki. Te dane wyjściowe mogą być wykorzystane do analizy lub wprowadzone jako dane wejściowe do innych aplikacji lub systemów uczenia maszynowego, dla których będą działać jako zalążek.
3. Szkolenie modelowe
Ten etap dotyczy stworzenia modelu na podstawie danych mu przekazanych. Na tym etapie część danych szkoleniowych jest wykorzystywana do znajdowania parametrów modelu, takich jak współczynniki wielomianu lub wagi uczenia maszynowego, co pomaga zminimalizować błąd dla danego zestawu danych. Pozostałe dane są następnie wykorzystywane do testowania modelu. Te dwa etapy są na ogół powtarzane kilka razy w celu poprawy wydajności modelu.
4. Wybór parametrów
Polega na wyborze parametrów związanych ze szkoleniem, które są również nazywane hiperparametrami. Te parametry kontrolują efektywność procesu szkolenia, a zatem ostatecznie zależy od tego wydajność modelu. Są one bardzo ważne dla udanej produkcji modelu uczenia maszynowego.
5. Transfer Learning
Ponieważ ponowne wykorzystanie modeli uczenia maszynowego w różnych domenach ma wiele zalet. Tak więc, pomimo faktu, że model nie może być przenoszony bezpośrednio między różnymi domenami, dlatego służy do zapewnienia materiału wyjściowego do rozpoczęcia szkolenia modelu następnego etapu. W ten sposób znacznie skraca czas szkolenia.
6. Weryfikacja modelu
Dane wejściowe na tym etapie to model wyuczony przez etap uczenia się modelu, a dane wyjściowe to model zweryfikowany, który zapewnia wystarczające informacje, aby umożliwić użytkownikom określenie, czy model jest odpowiedni do zamierzonego zastosowania. Dlatego ten etap cyklu uczenia maszynowego dotyczy faktu, że model działa poprawnie, gdy jest przetwarzany za pomocą niewidocznych danych wejściowych.
7. Wdróż model uczenia maszynowego
Na tym etapie cyklu uczenia maszynowego ubiegamy się o zintegrowanie modeli uczenia maszynowego z procesami i aplikacjami. Ostatecznym celem tego etapu jest odpowiednia funkcjonalność modelu po wdrożeniu. Modele powinny być wdrażane w taki sposób, aby można je było wykorzystywać do wnioskowania, a także powinny być regularnie aktualizowane.
8. Monitorowanie
Obejmuje to włączenie środków bezpieczeństwa w celu zapewnienia prawidłowego działania modelu w całym okresie jego użytkowania. Aby tak się stało, wymagane jest odpowiednie zarządzanie i aktualizacja.
Zaleta cyklu życia uczenia maszynowego
Uczenie maszynowe zapewnia korzyści płynące z mocy, szybkości, wydajności i inteligencji poprzez uczenie się bez jawnego programowania ich w aplikacji. Zapewnia możliwości poprawy wydajności, wydajności i niezawodności.
Wniosek - Cykl życia uczenia maszynowego
Systemy uczenia maszynowego stają się coraz ważniejsze z dnia na dzień, ponieważ ilość danych wykorzystywanych w różnych aplikacjach szybko rośnie. Technologia uczenia maszynowego jest sercem inteligentnych urządzeń, sprzętu gospodarstwa domowego i usług online. Sukces uczenia maszynowego można rozszerzyć na systemy o kluczowym znaczeniu dla bezpieczeństwa, zarządzanie danymi, obliczenia o wysokiej wydajności, które mają ogromny potencjał w domenach aplikacji.
Polecane artykuły
Jest to przewodnik po cyklu uczenia się maszynowego. Tutaj omawiamy wprowadzenie, Uczenie się na błędach, Kroki związane z cyklem życia uczenia maszynowego i zalety. Możesz także przejrzeć nasze inne sugerowane artykuły, aby dowiedzieć się więcej -
- Firmy sztucznej inteligencji
- Analiza zestawu QlikView
- Ekosystem IoT
- Modelowanie danych Cassandra