

Wprowadzenie do poleceń Spark
Apache Spark to platforma zbudowana na platformie Hadoop do szybkich obliczeń. Rozszerza koncepcję MapReduce w scenariuszu opartym na klastrze, aby efektywnie uruchomić zadanie. Spark Command jest napisany w języku Scala.
Hadoop może być wykorzystywany przez Spark na następujące sposoby (patrz poniżej):
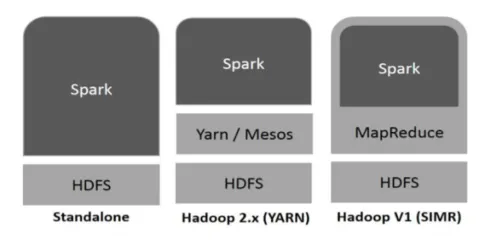
Ryc.1
https://www.tutorialspoint.com/
- Autonomiczny: Spark bezpośrednio wdrożony na platformie Hadoop. Zadania Spark działają równolegle na platformach Hadoop i Spark.
- Hadoop YARN: Spark działa na Yarn bez potrzeby wstępnej instalacji.
- Spark w MapReduce (SIMR): Spark w MapReduce służy do uruchamiania zadania Spark oprócz samodzielnego wdrażania. Dzięki SIMR można uruchomić Spark i używać jego powłoki bez żadnego dostępu administracyjnego.
Składniki Spark:
- Apache Spark Core
- Spark SQL
- Spark Streaming
- MLib
- GraphX
Resilient Distributed Datasets (RDD) jest uważany za podstawową strukturę danych poleceń Spark. RDD jest niezmienny i ma charakter tylko do odczytu. Wszelkiego rodzaju obliczenia w poleceniach Spark są wykonywane przez transformacje i działania na RDD.
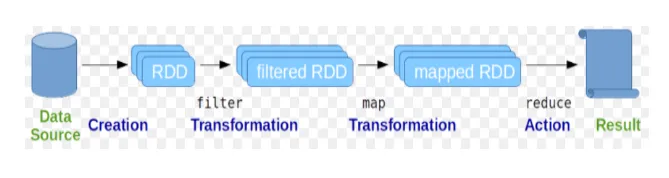
Ryc. 2
Obraz Google
Spark Shell zapewnia użytkownikom możliwość interakcji z jego funkcjami. Polecenia Spark mają wiele różnych poleceń, których można użyć do przetwarzania danych w interaktywnej powłoce.
Podstawowe komendy Spark
Rzućmy okiem na niektóre z podstawowych poleceń Spark, które są podane poniżej: -
-
Aby uruchomić powłokę Spark:

Ryc. 3
-
Odczytaj plik z systemu lokalnego:

Tutaj „sc” jest kontekstem iskier. Biorąc pod uwagę, że „data.txt” znajduje się w katalogu domowym, jest on czytany w ten sposób, w przeciwnym razie należy podać pełną ścieżkę.
-
Stwórz RDD poprzez równoległość

NewData jest teraz RDD.
-
Policz przedmioty w RDD

-
Zebrać
Ta funkcja zwraca całą zawartość RDD do programu sterownika. Jest to pomocne w debugowaniu na różnych etapach programu do pisania.
-
Przeczytaj pierwsze 3 pozycje z RDD

-
Zapisz dane wyjściowe / przetworzone w pliku tekstowym

Tutaj folder „wyjściowy” jest bieżącą ścieżką.
Pośrednie polecenia iskier
1. Filtruj według RDD
Utwórzmy nowy RDD dla pozycji zawierających „tak”.

Na istniejącym RDD należy wywołać filtr transformacji, aby odfiltrować słowo „tak”, co spowoduje utworzenie nowego RDD z nową listą elementów.
2. Operacja łańcuchowa

Tutaj filtrowanie transformacji i liczenie działały razem. Nazywa się to operacją łańcuchową.
3. Przeczytaj pierwszy element z RDD

4. Policz partycje RDD
Jak wiemy, RDD składa się z wielu partycji, pojawia się potrzeba policzenia nie. partycji. Jak to pomaga w dostrajaniu i rozwiązywaniu problemów podczas pracy z poleceniami Spark.

Domyślnie minimum nie. partycja pf to 2.
5. dołącz
Ta funkcja łączy dwie tabele (element tabeli jest parowany) na podstawie wspólnego klucza. W RDD parami pierwszy element jest kluczem, a drugi element jest wartością.
6. Buforuj plik
Buforowanie to technika optymalizacji. Buforowanie RDD oznacza, że RDD pozostanie w pamięci, a wszystkie przyszłe obliczenia zostaną wykonane na tych RDD w pamięci. Oszczędza czas odczytu dysku i poprawia wydajność. Krótko mówiąc, skraca czas dostępu do danych.

Jednak dane nie będą buforowane, jeśli uruchomisz powyżej funkcji. Można to udowodnić odwiedzając stronę internetową:
http: // localhost: 4040 / storage
RDD będzie buforowane, gdy akcja zostanie wykonana. Na przykład:

Kolejną funkcją, która działa podobnie do cache () jest persist (). Utrwalanie daje użytkownikom elastyczność w argumentowaniu, co może pomóc w buforowaniu danych w pamięci, na dysku lub w pamięci poza stosem. Utrwalanie bez żadnego argumentu działa tak samo jak cache ().
Zaawansowane komendy Spark
Rzućmy okiem na niektóre z zaawansowanych poleceń Spark, które są podane poniżej: -
-
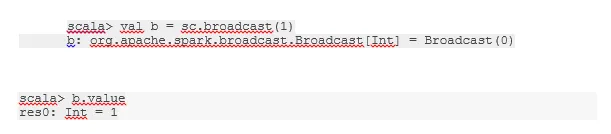
Nadaj zmienną
Zmienna rozgłoszeniowa pomaga programiście w dalszym ciągu czytać jedyną zmienną zapisaną w pamięci podręcznej na każdym komputerze w klastrze, zamiast dostarczać kopię tej zmiennej z zadaniami. Pomaga to w obniżeniu kosztów komunikacji.
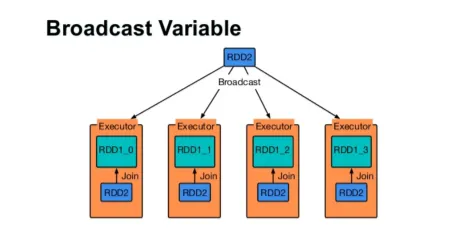
Ryc. 4
Google Image
Krótko mówiąc, istnieją trzy główne cechy zmiennej Broadcasted:
- Niezmienny
- Wpadnij w pamięć
- Rozłożone na klaster
-
Akumulatory
Akumulatory to zmienne dodawane do powiązanych operacji. Istnieje wiele zastosowań akumulatorów, takich jak liczniki, sumy itp.

Nazwę akumulatora w kodzie można również zobaczyć w interfejsie Spark.
-
Mapa
Funkcja mapy pomaga w iteracji po każdej linii RDD. Funkcja używana w mapie jest stosowana do każdego elementu w RDD.
Na przykład w RDD (1, 2, 3, 4, 6), jeśli zastosujemy „rdd.map (x => x + 2)”, otrzymamy wynik jako (3, 4, 5, 6, 8).
-
Flatmap
Flatmap działa podobnie do mapy, ale mapa zwraca tylko jeden element, podczas gdy flatmap może zwrócić listę elementów. Dlatego dzielenie zdań na słowa będzie wymagało płaskiej mapy.
-
Łączyć
Ta funkcja pomaga uniknąć przetasowania danych. Jest to stosowane w istniejącej partycji, dzięki czemu mniej danych jest tasowanych. W ten sposób możemy ograniczyć użycie węzłów w klastrze.
Wskazówki i porady dotyczące używania poleceń Spark
Poniżej znajdują się różne wskazówki i polecenia poleceń Spark: -
- Początkujący Spark mogą używać Spark-shell. Ponieważ polecenia Spark są zbudowane na Scali, z pewnością używanie iskierki Scala jest świetne. Jednak dostępna jest również powłoka iskrowa Pythona, więc nawet tego można użyć, którzy dobrze znają Pythona.
- Spark Shell ma wiele opcji zarządzania zasobami klastra. Poniższe polecenie może ci w tym pomóc:

- W Spark praca z długimi zestawami danych jest czymś normalnym. Ale coś pójdzie nie tak, gdy zostaną podjęte złe dane wejściowe. Zawsze dobrym pomysłem jest upuszczanie złych wierszy za pomocą funkcji filtrowania Spark. Dobry zestaw danych wejściowych będzie świetny.
- Spark sam wybiera dobrą partycję dla danych. Ale zawsze dobrą praktyką jest pilnowanie partycji przed rozpoczęciem pracy. Wypróbowanie różnych partycji pomoże ci w równoległości pracy.
Wniosek - komendy Spark:
Polecenie Spark to rewolucyjny i wszechstronny silnik dużych zbiorów danych, który może pracować z przetwarzaniem wsadowym, przetwarzaniem w czasie rzeczywistym, buforowaniem danych itp. Spark ma bogaty zestaw bibliotek uczenia maszynowego, które umożliwiają naukowcom danych i organizacjom analitycznym tworzenie silnych, interaktywnych i szybkie aplikacje.
Polecane artykuły
To był przewodnik po poleceniach Spark. Omówiliśmy tutaj zarówno podstawowe, jak i zaawansowane polecenia Spark oraz niektóre natychmiastowe polecenia Spark. Możesz także spojrzeć na następujący artykuł, aby dowiedzieć się więcej -
- Polecenia Adobe Photoshop
- Ważne polecenia VBA
- Polecenia Tableau
- Ściągawka SQL (polecenia, darmowe porady i triki)
- Rodzaje złączeń w Spark SQL (przykłady)
- Komponenty iskrowe | Przegląd i 6 najważniejszych komponentów