
Wprowadzenie do technik ensemble
Uczenie się w zespole jest techniką uczenia maszynowego, która wykorzystuje kilka podstawowych modeli i łączy ich wyniki w celu uzyskania zoptymalizowanego modelu. Ten typ algorytmu uczenia maszynowego pomaga w poprawie ogólnej wydajności modelu. Tutaj najczęściej stosowanym modelem podstawowym jest klasyfikator drzewa decyzyjnego. Drzewo decyzyjne zasadniczo działa na kilku regułach i zapewnia wyniki predykcyjne, w których reguły są węzłami, a ich decyzje będą ich dziećmi, a węzły liści będą ostateczną decyzją. Jak pokazano na przykładzie drzewa decyzyjnego.
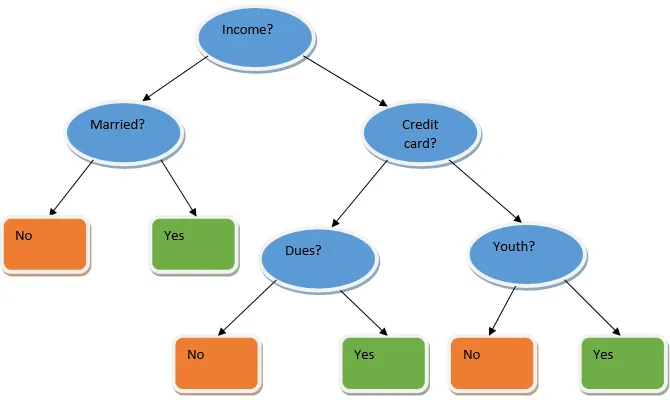
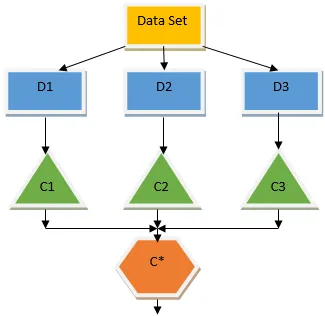
Powyższe drzewo decyzyjne zasadniczo mówi o tym, czy dana osoba / klient może otrzymać pożyczkę, czy nie. Jedną z zasad kwalifikowalności pożyczki jest to, że jeśli (dochód = tak i & Married = nie), to pożyczka = tak, tak działa klasyfikator drzewa decyzyjnego. Uwzględnimy te klasyfikatory jako model wielu baz i połączymy ich wyniki, aby stworzyć jeden optymalny model predykcyjny. Rysunek 1.b pokazuje ogólny obraz algorytmu uczenia się w zespole.
Rodzaje technik zespołów
Różne typy zespołów, ale naszym głównym celem będą dwa poniższe typy:
- Parcianka
- Boosting
Te metody pomagają zmniejszyć wariancję i stronniczość w modelu uczenia maszynowego. Teraz spróbujmy zrozumieć, co to jest stronniczość i wariancja. Odchylenie jest błędem, który występuje z powodu nieprawidłowych założeń w naszym algorytmie; wysokie odchylenie wskazuje, że nasz model jest zbyt prosty / niedostateczny. Wariancja to błąd spowodowany wrażliwością modelu na bardzo małe fluktuacje w zbiorze danych; duża wariancja wskazuje, że nasz model jest bardzo skomplikowany / nadmierny. Idealny model ML powinien mieć właściwą równowagę między stronniczością a wariancją.
Bootstrap Agregacja / workowanie
Bagging to kompleksowa technika, która pomaga zmniejszyć wariancję w naszym modelu, a tym samym pozwala uniknąć nadmiernego dopasowania. Tworzenie worków jest przykładem algorytmu uczenia równoległego. Pakowanie działa w oparciu o dwie zasady.
- Ładowanie początkowe : z oryginalnego zestawu danych rozważane są różne populacje próbne z zastąpieniem.
- Agregowanie: Uśrednianie wyników wszystkich klasyfikatorów i zapewnianie pojedynczego wyniku, w tym celu wykorzystuje głosowanie większością w przypadku klasyfikacji i uśrednianie w przypadku problemu z regresją. Jednym ze słynnych algorytmów uczenia maszynowego wykorzystujących koncepcję workowania jest losowy las.
Losowy las
W losowym lesie z losowej próbki pobranej z populacji z podmianą i ze zbioru wszystkich elementów jest wybierany podzbiór cech, w których budowane jest drzewo decyzyjne. Z tych podzbiorów funkcji, która z opcji daje najlepszy podział, wybrano jako podstawę drzewa decyzyjnego. Podzbiór funkcji należy wybierać losowo za wszelką cenę, w przeciwnym razie produkujemy tylko skorelowane warkocze, a wariancja modelu nie ulegnie poprawie.
Teraz zbudowaliśmy nasz model na próbkach pobranych z populacji. Pytanie brzmi: w jaki sposób weryfikujemy model? Ponieważ rozważamy próbki z wymianą, dlatego wszystkie próbki nie będą brane pod uwagę, a niektóre z nich nie zostaną uwzględnione w żadnej torbie, są one nazywane próbkami poza torbą. Możemy zweryfikować nasz model za pomocą próbek OOB (z worka). Ważnymi parametrami, które należy wziąć pod uwagę w losowym lesie, jest liczba próbek i liczba drzew. Rozważmy „m” jako podzbiór funkcji, a „p” to pełny zestaw funkcji, teraz jako ogólna zasada, zawsze idealnie jest wybierać
- m as√ i minimalny rozmiar węzła równy 1 dla problemu klasyfikacji.
- m jako P / 3 i minimalny rozmiar węzła to 5 dla problemu regresji.
M i p należy traktować jako parametry strojenia, gdy mamy do czynienia z problemem praktycznym. Trening można zakończyć po ustabilizowaniu się błędu OOB. Wadą losowego lasu jest to, że gdy mamy 100 funkcji w naszym zbiorze danych i tylko kilka cech jest ważnych, algorytm ten będzie działał słabo.
Boosting
Wzmocnienie jest algorytmem uczenia sekwencyjnego, który pomaga zmniejszyć stronniczość w naszym modelu i wariancję w niektórych przypadkach nadzorowanego uczenia się. Pomaga również w przekształcaniu słabych uczniów w silnych uczniów. Wzmocnienie działa na zasadzie umieszczania słabych uczniów po kolei i przypisuje wagę każdemu punktowi danych po każdej rundzie; większa waga przypisywana jest do błędnie sklasyfikowanego punktu danych w poprzedniej rundzie. Ta sekwencyjna ważona metoda szkolenia naszego zestawu danych jest kluczową różnicą w stosunku do workowania.
Ryc. 3.a pokazuje ogólne podejście do wzmacniania
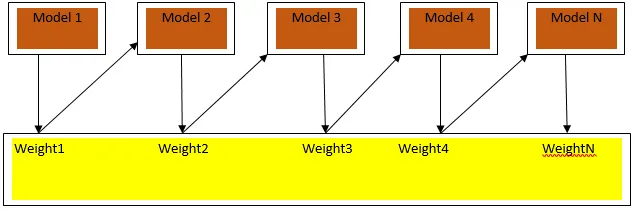
Ostateczne prognozy są łączone na podstawie głosowania większością ważoną w przypadku klasyfikacji i sumy ważonej w przypadku regresji. Najczęściej stosowanym algorytmem doładowania jest adaptacyjne doładowanie (Adaboost).
Adaptacyjne wzmocnienie
Kroki związane z algorytmem Adaboost są następujące:
- Dla podanych n punktów danych definiujemy klasę docelową i inicjalizujemy wszystkie wagi do 1 / n.
- Dopasowujemy klasyfikatory do zestawu danych i wybieramy klasyfikację z najmniejszym błędem klasyfikacji
- Przypisujemy wagi do klasyfikatora za pomocą reguły kciuka na podstawie dokładności, jeśli dokładność jest większa niż 50%, wówczas waga jest dodatnia i odwrotnie.
- Aktualizujemy wagi klasyfikatorów pod koniec iteracji; aktualizujemy większą wagę błędnie sklasyfikowanego punktu, aby w następnej iteracji poprawnie go sklasyfikować.
- Po całej iteracji otrzymujemy ostateczny wynik prognozy na podstawie większości głosów / średniej ważonej.
Adaboosting działa skutecznie z słabymi (mniej złożonymi) uczniami i z dużymi klasyfikatorami uprzedzeń. Główną zaletą Adaboosting jest to, że jest szybki, nie ma parametrów dostrajania podobnych do przypadku workowania i nie przyjmujemy żadnych założeń dotyczących słabych uczniów. Ta technika nie zapewnia dokładnego wyniku, kiedy
- W naszych danych jest więcej wartości odstających.
- Zestaw danych jest niewystarczający.
- Słabe osoby uczące się są bardzo złożone.
Są również podatne na hałas. Drzewa decyzyjne powstałe w wyniku wzmocnienia będą miały ograniczoną głębokość i wysoką dokładność.
Wniosek
Techniki uczenia się w zespole są szeroko stosowane w celu poprawy dokładności modelu; musimy zdecydować, jakiej techniki użyć na podstawie naszego zestawu danych. Ale te techniki nie są preferowane w niektórych przypadkach, w których interpretacja jest ważna, ponieważ tracimy interpretowalność kosztem poprawy wydajności. Mają one ogromne znaczenie w branży opieki zdrowotnej, w której niewielka poprawa wydajności jest bardzo cenna.
Polecane artykuły
To jest przewodnik po Ensemble Techniques. Tutaj omawiamy wprowadzenie i dwa główne typy technik zespołu. Możesz również przejrzeć nasze inne powiązane artykuły, aby dowiedzieć się więcej-
- Techniki steganograficzne
- Techniki uczenia maszynowego
- Techniki budowania zespołu
- Algorytmy nauki danych
- Najczęściej stosowane techniki uczenia się w zespole