
Wprowadzenie do regresji Poissona w R.
Regresja Poissona jest rodzajem regresji podobnej do wielokrotnej regresji liniowej, z tym wyjątkiem, że odpowiedź lub zmienna zależna (Y) jest zmienną zliczającą. Zmienna zależna podąża za rozkładem Poissona. Predyktory lub zmienne niezależne mogą mieć charakter ciągły lub kategoryczny. W pewnym sensie jest podobny do regresji logistycznej, która ma również zmienną dyskretną odpowiedź. Wcześniejsze zrozumienie rozkładu Poissona i jego formy matematycznej jest bardzo istotne, aby wykorzystać go do przewidywania. W R regresję Poissona można wdrożyć w bardzo skuteczny sposób. R oferuje kompleksowy zestaw funkcji do jego wdrożenia.
Wdrażanie regresji Poissona
Teraz przejdziemy do zrozumienia, w jaki sposób zastosowano model. Poniższa sekcja zawiera procedurę krok po kroku dla tego samego. Do tej demonstracji rozważamy zestaw danych „gala” z pakietu „daleki”. Dotyczy różnorodności gatunków na Wyspach Galapagos. Zestaw danych zawiera łącznie 7 zmiennych. Użyjemy regresji Poissona do zdefiniowania związku między liczbą gatunków roślin (gatunków) z innymi zmiennymi w zbiorze danych.
1. Najpierw załaduj pakiet „daleki”. Jeśli pakiet nie jest obecny, pobierz go za pomocą funkcji install.packages ().
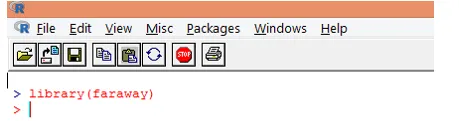
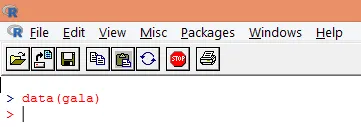
2. Po załadowaniu pakietu załaduj zestaw danych „gala” do R za pomocą funkcji data (), jak pokazano poniżej.
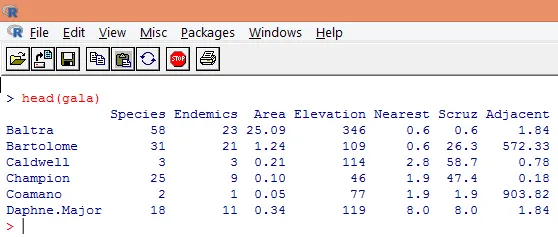
3. Załadowane dane należy wizualizować, aby zbadać zmienną i sprawdzić, czy występują jakieś rozbieżności. Możemy wizualizować albo całe dane, albo tylko kilka pierwszych wierszy za pomocą funkcji head (), jak pokazano na poniższym zrzucie ekranu.
4. Aby uzyskać lepszy wgląd w zestaw danych, możemy użyć funkcji pomocy w języku R, jak poniżej. Generuje dokumentację R, jak pokazano na zrzucie ekranu po poniższym zrzucie ekranu.


5. Jeśli przestudiujemy zestaw danych, jak wspomniano w poprzednich krokach, możemy stwierdzić, że Gatunek jest zmienną odpowiedzi. Przeanalizujemy teraz podstawowe podsumowanie zmiennych predykcyjnych.
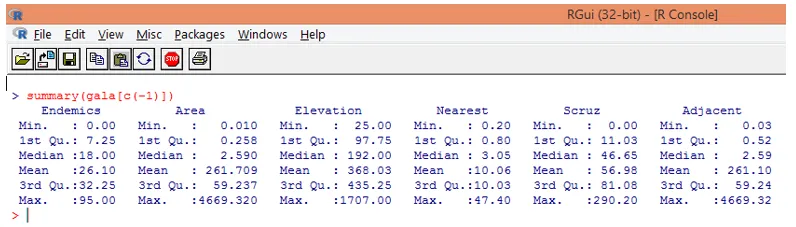
Uwaga: jak widać powyżej, wykluczyliśmy zmienną Gatunki. Funkcja podsumowania daje nam podstawowe informacje. Wystarczy obserwować wartości mediany dla każdej z tych zmiennych, i możemy stwierdzić, że między pierwszą połową a drugą połową istnieje ogromna różnica, jeśli chodzi o zakres wartości, np. Dla mediany wartości zmiennej Area wynosi 2, 59, ale maksymalna wartość wynosi 4669.320.
6. Po zakończeniu podstawowej analizy wygenerujemy histogram dla gatunków, aby sprawdzić, czy zmienna jest zgodna z rozkładem Poissona. Zilustrowano to poniżej.

Powyższy kod generuje histogram dla zmiennej gatunku wraz z nałożoną na nią krzywą gęstości.
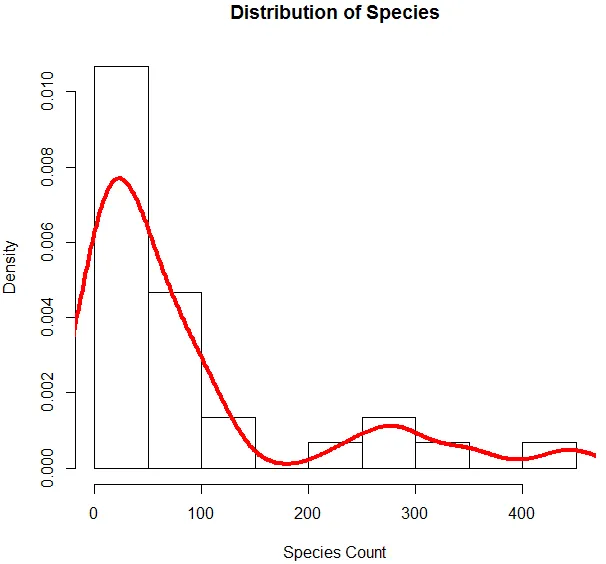
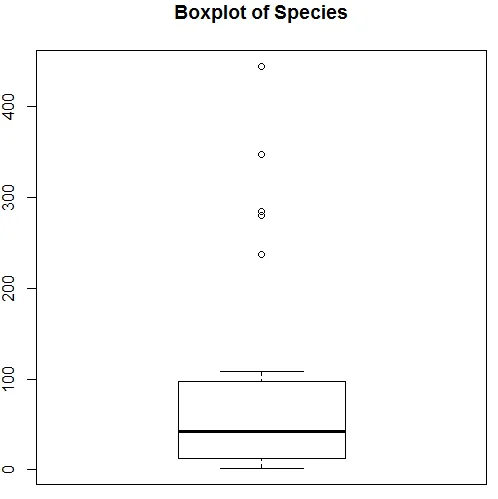
Powyższa wizualizacja pokazuje, że Gatunek ma rozkład Poissona, ponieważ dane są wypaczone w prawo. Możemy również wygenerować wykres pudełkowy, aby uzyskać lepszy wgląd w schemat dystrybucji, jak pokazano poniżej.
7. Po zakończeniu wstępnej analizy zastosujemy teraz regresję Poissona, jak pokazano poniżej
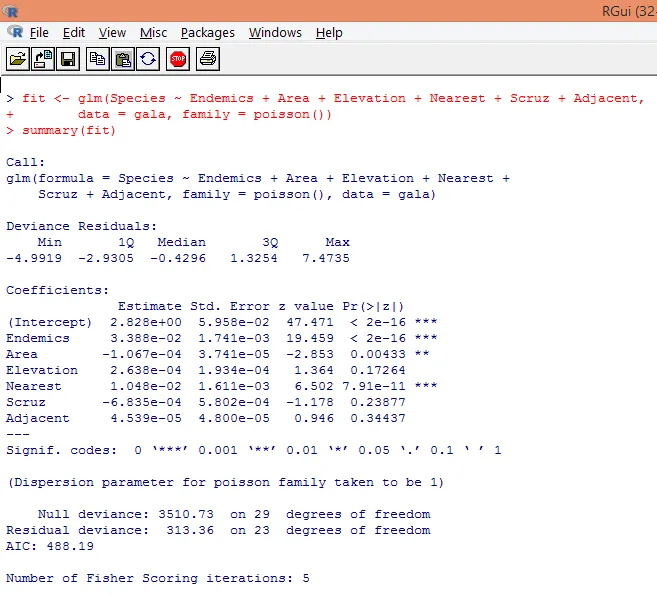
Na podstawie powyższej analizy stwierdzamy, że zmienne Endemiczne, Obszar i Najbliższe są znaczące i tylko ich włączenie jest wystarczające do zbudowania odpowiedniego modelu regresji Poissona.
8. Zbudujemy zmodyfikowany model regresji Poissona, biorąc pod uwagę tylko trzy zmienne, a mianowicie. Endemiczne, obszarowe i najbliższe. Zobaczmy, jakie wyniki otrzymamy.
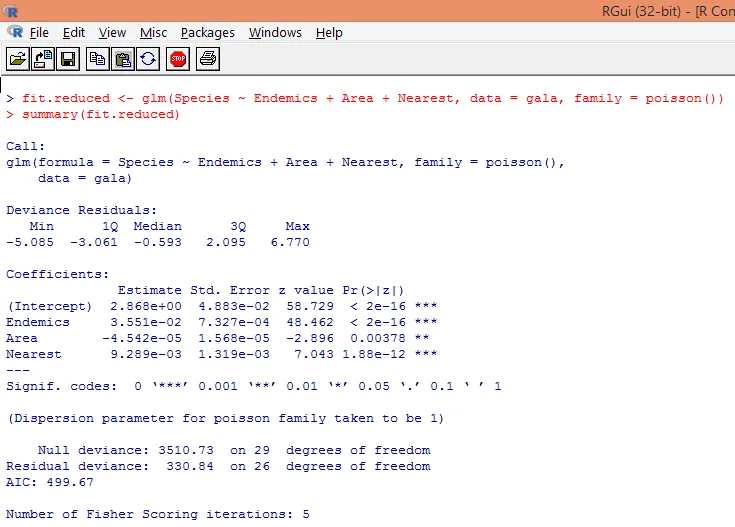
Dane wyjściowe powodują odchylenia, parametry regresji i błędy standardowe. Widzimy, że każdy z parametrów jest istotny na poziomie p <0, 05.
9. Kolejnym krokiem jest interpretacja parametrów modelu. Współczynniki modelu można uzyskać, badając współczynniki w powyższym wyniku lub używając funkcji coef ().
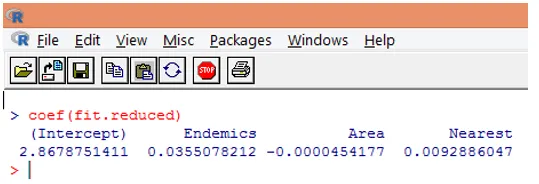
W regresji Poissona zmienna zależna jest modelowana jako log logarytmicznej średniej loge (l). Parametr regresji 0, 0355 dla Endemics wskazuje, że wzrost o jedną jednostkę zmiennej jest związany ze wzrostem o 0, 04 średniej logarytmicznej liczby gatunków, utrzymując stałe inne zmienne. Punkt przecięcia to logarytmiczna średnia liczba gatunków, gdy każdy z predyktorów jest równy zero.
10. Znacznie łatwiej jest jednak interpretować współczynniki regresji w oryginalnej skali zmiennej zależnej (liczba gatunków, a nie liczba logów gatunków). Potęgowanie współczynników pozwoli na łatwą interpretację. Odbywa się to w następujący sposób.
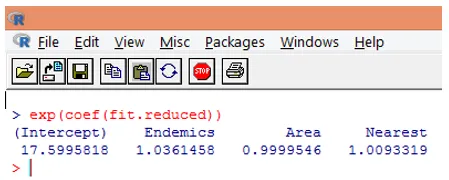
Z powyższych ustaleń możemy stwierdzić, że wzrost o jedną jednostkę w obszarze zwielokrotnia oczekiwaną liczbę gatunków o 0, 9999, a wzrost w jednostce liczby gatunków endemicznych reprezentowanych przez endemikę zwielokrotnia liczbę gatunków o 1, 0361. Najważniejszym aspektem regresji Poissona jest to, że parametry potęgowane mają raczej efekt multiplikatywny niż addytywny względem zmiennej odpowiedzi.
11. Korzystając z powyższych kroków, otrzymaliśmy model regresji Poissona do przewidywania liczby gatunków roślin na Wyspach Galapagos. Jednak bardzo ważne jest sprawdzenie nadmiernej dyspersji. W regresji Poissona wariancja i średnie są równe.
Nadmierna dyspersja występuje, gdy zaobserwowana wariancja zmiennej odpowiedzi jest większa niż byłaby przewidywana na podstawie rozkładu Poissona. Analiza naddyspersji staje się ważna, ponieważ jest powszechna w danych zliczania i może negatywnie wpłynąć na ostateczne wyniki. W R, naddyspersję można analizować za pomocą pakietu „qcc”. Analiza jest zilustrowana poniżej.
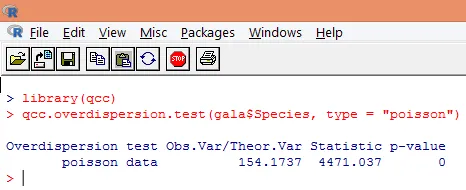
Powyższy znaczący test pokazuje, że wartość p jest mniejsza niż 0, 05, co zdecydowanie sugeruje obecność nadmiernej dyspersji. Spróbujemy dopasować model za pomocą funkcji glm (), zastępując family = „Poisson” przez family = „quasipoisson”. Zilustrowano to poniżej.
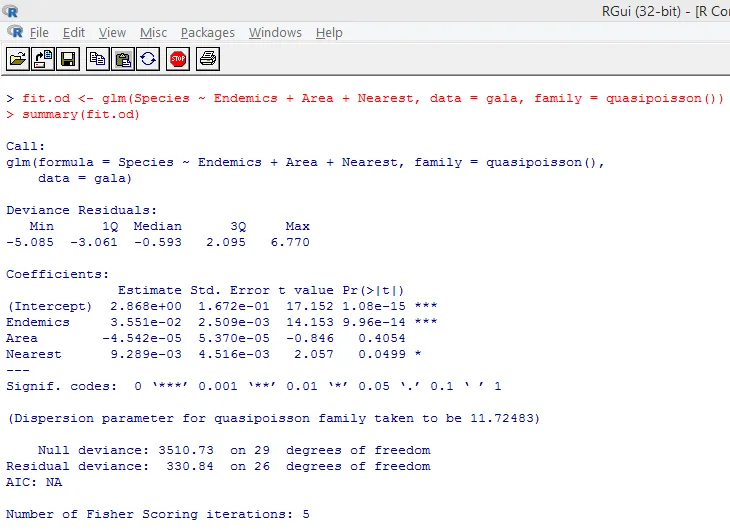
Dokładnie badając powyższe dane wyjściowe, możemy zauważyć, że szacunki parametrów w podejściu quasi-Poissona są identyczne z oszacowaniami uzyskanymi w podejściu Poissona, chociaż standardowe błędy są różne dla obu podejść. Ponadto, w tym przypadku, dla pola wartość p jest większa niż 0, 05, co wynika z większego błędu standardowego.
Znaczenie regresji Poissona
- Regresja Poissona w R jest przydatna do poprawnego przewidywania zmiennej dyskretnej / zliczającej.
- Pomaga nam zidentyfikować zmienne objaśniające, które mają statystycznie istotny wpływ na zmienną odpowiedzi.
- Regresja Poissona w R najlepiej nadaje się do wydarzeń o „rzadkiej” naturze, ponieważ mają one tendencję do podążania za rozkładem Poissona w porównaniu z typowymi zdarzeniami, które zwykle mają rozkład normalny.
- Jest odpowiedni do zastosowania w przypadkach, gdy zmienna odpowiedzi jest małą liczbą całkowitą.
- Ma szerokie zastosowanie, ponieważ przewidywanie zmiennych dyskretnych jest kluczowe w wielu sytuacjach. W medycynie można go wykorzystać do przewidywania wpływu leku na zdrowie. Jest szeroko stosowany w analizach przeżycia, takich jak śmierć organizmów biologicznych, awaria układów mechanicznych itp.
Wniosek
Regresja Poissona opiera się na koncepcji rozkładu Poissona. Jest to kolejna kategoria należąca do zestawu technik regresji, która łączy właściwości regresji zarówno liniowej, jak i logistycznej. Jednak w przeciwieństwie do regresji logistycznej, która generuje tylko dane binarne, służy do przewidywania zmiennej dyskretnej.
Polecane artykuły
To jest przewodnik po regresji Poissona w R. Tutaj omawiamy wprowadzenie Wdrażanie regresji Poissona i znaczenie regresji Poissona. Możesz także przejrzeć nasze inne sugerowane artykuły, aby dowiedzieć się więcej -
- GLM w R.
- Generator liczb losowych w R.
- Formuła regresji
- Regresja logistyczna w R.
- Regresja liniowa a regresja logistyczna | Najważniejsze różnice