
Różnica między HBase a Cassandrą
HBase to baza danych, która używa rozproszonego systemu plików Hadoop do przechowywania. HBase jest ważną częścią HDFS i działa na klastrze Hadoop. HBase nie jest tradycyjną relacyjną bazą danych, wymaga innego podejścia do modelowania danych. Cassandra działa na modelu replikacji danych, więc w przypadku niedostępności dowolnego węzła nie nastąpi utrata danych. Cassandra to rozproszona baza danych, dzięki której klient może uzyskać dostęp do dowolnego klastra i dowolnego węzła
1.1) Cassandra:
Zostało uruchomione przez Facebooka, ponieważ zawsze wymaga spełnienia wymagań aplikacji. Cassandra została uruchomiona w 2005 roku i udostępniona publicznie w 2008 roku. Cassandra została opracowana dla aplikacji, które są zawsze dostępne, takich jak sieci społecznościowe, takie jak Facebook i Twitter.
Cassandra pracuje na „zawsze włączonej” architekturze i ma aktywny model węzła, więc nie ma SPoF (Pojedynczy punkt awarii). CQL (Cassandra Query Language) jest językiem zapytań Cassandry, ale ma taką samą składnię jak SQL. Obsługuje wszystkie główne systemy operacyjne, takie jak Linux, Unix, OSX i Windows.
Zawsze włączone:
Cassandra to baza danych z modelem dystrybucji, a wszystkie węzły są takie same w klastrze. Dane są replikowane w konfigurowalnych węzłach, więc w przypadku awarii niektórych nie. węzłów nie spowoduje utraty danych.
(Zawsze w modelu)
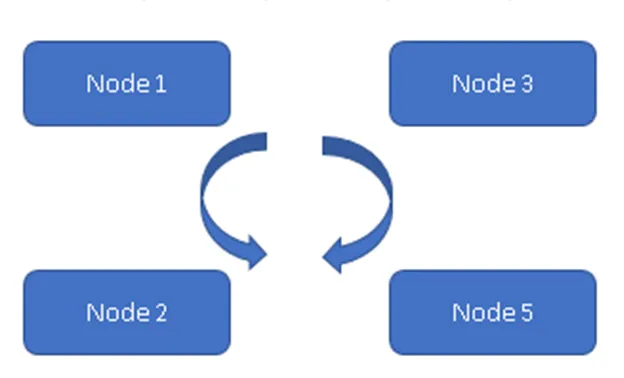
Na rysunku 1 wszystkie cztery węzły są zsynchronizowane i replikują dane w klastrze. Wszyscy pracują na modelu Active-Active, więc w przypadku awarii węzła nie spowoduje to utraty danych. Klient może odczytać dane z pozostałej części dostępnego węzła / węzłów.
1.2) HBase:
HBase jest bazą danych opartą na NoSQL i zaprojektowaną do przetwarzania zapytań w dużych tabelach o miliardach wierszy z milionami kolumn i przebiegających przez klaster towarowy / normalny sprzęt. Zapewnia możliwości zapytań w czasie rzeczywistym z prędkością „ magazynu kluczy / wartości ” .
HBase faktycznie opiera się / działa na czterowymiarowym modelu danych.
- Identyfikator wiersza / klucz wiersza
- Rodzina kolumn.
- Pary klucz-wartość.
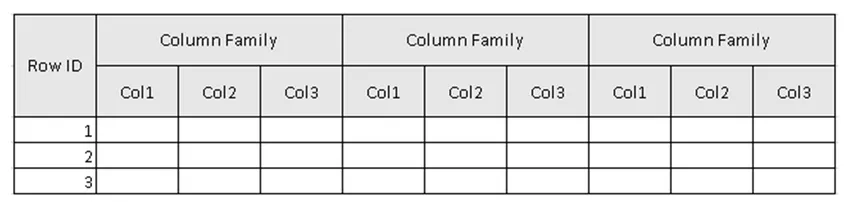
(Rysunek 2, Przykładowy schemat tabeli w HBase.)
Na rysunku 2 tabela to zbiór rodziny kolumn, a rodzina kolumn to zbiór kolumn. Kolumny to zbiór par klucz-wartość
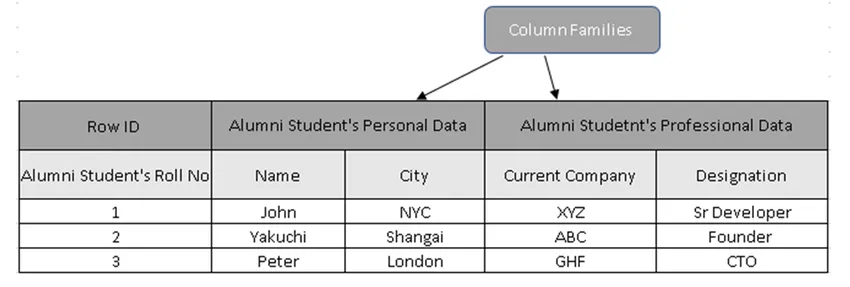
(Ryc. 3, Tabela próbek w HBase)
Na rycinie 3 rodziny kolumn są zbiorem danych absolwentów, a identyfikatory wierszy (klucze wierszy) zawierają numer rzutu studenta
Faktycznie, klucze wierszy przechowują unikalną wartość względem danych rodziny kolumn. Za pomocą klucza wiersza można wyodrębnić wszystkie szczegóły, powody, dla których bazy danych zorientowane na kolumny są znacznie szybsze niż tradycyjne bazy danych.
Apache HBase może być używany do losowego odczytu / zapisu i zapewnia obsługę błędów. Obsługuje również replikację i pracę nad modelem dystrybucji bazy danych.
Bezpośrednie porównanie HBase vs Cassandra (infografiki)
Poniżej znajduje się 9 najważniejszych różnic między HBase a Cassandrą
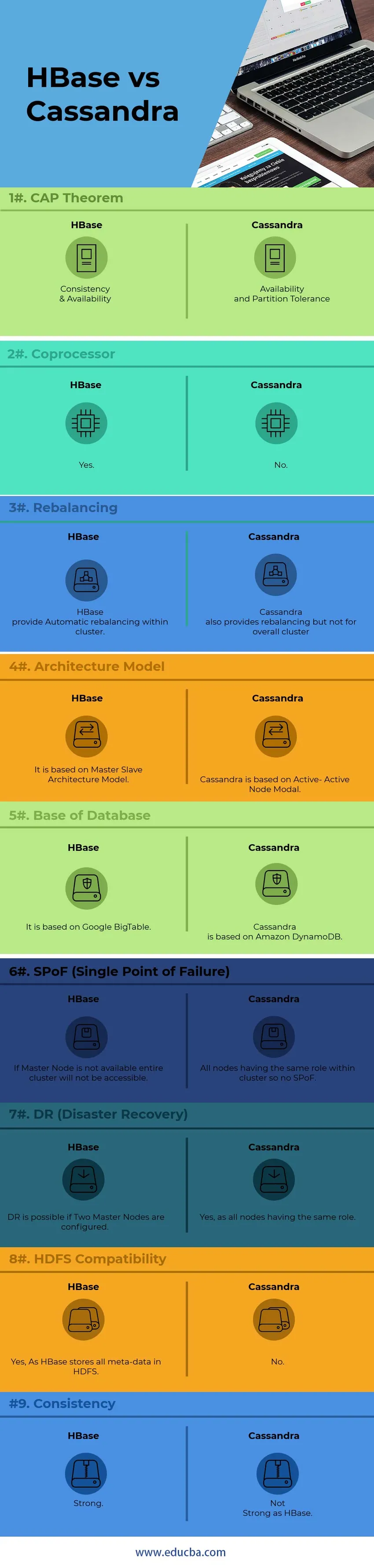 Kluczowe różnice między HBase a Cassandrą
Kluczowe różnice między HBase a Cassandrą
Poniżej znajdują się listy punktów, opisz kluczowe różnice między HBase a Cassandrą:
1) Do komunikacji w węźle wewnętrznym Cassandra używa protokołu GOSSIP, podczas gdy HBase jest oparty na Zookeeper. Usługi protokołu GOSSIP są zintegrowane z Cassandrą po drugiej stronie Zookeeper jest całkowicie oddzielną aplikacją dystrybucyjną.
2) W architekturze Cassandra wszystkie węzły działają jako aktywny węzeł, podczas gdy architekt HBase postępuje zgodnie z modelem węzła Master-Slave. W modelu Active-Active Node nie występuje SPoF (pojedynczy punkt awarii). W HBase, jeśli węzeł główny ulegnie awarii, cały klaster nie będzie dostępny.
3) Obsługa HBase Model wyszukiwania drzewa binarnego, podczas gdy Cassandra nie obsługuje modelu B-Tree Bez B-Tree nie można przeszukiwać rodziny kolumn użytkownika dla wszystkich osób z rocznicą w kwietniu, podczas gdy można wyszukiwać wszystkich, którzy mieszkają w Pekinie z Rocznica w kwietniu.
4) HBase, obsługa języków skryptowych C, C ++, Java, Python, Scala, a Cassandra obsługuje także JavaScript i Ruby.
5) HBase ma jedną funkcję zwaną koprocesorami, podczas gdy Cassandra nie ma takiej funkcji jak na razie. Koprocesory zapewniają bibliotekę i środowisko wykonawcze do wykonywania kodu użytkownika na serwerze regionu HBase i procesach głównych.
6) HBase został zaprojektowany do obsługi hurtowni danych, a Cassandra będzie idealna do wszechstronnych aplikacji, takich jak aplikacje internetowe i mobilne.
7) Język zapytań HBase jest językiem niestandardowym, którego należy się nauczyć, podczas gdy Cassandra używa własnego opracowanego języka CQL (Cassandra Query Language), który jest językiem podobnym do SQL
8) Zarządzanie Cassandrą jest znacznie łatwiejsze niż HBase. W Cassandrze należy uruchomić jeden proces Java dla każdego węzła, natomiast w przypadku HBase wymagany jest w pełni operacyjny HDFS, kilka procesów HBase i system Zookeeper.
9) HBase dokonuje sum kontrolnych i automatycznego równoważenia, podczas gdy Cassandra nie obsługuje ogólnego równoważenia klastra.
10) Na podstawie „ Twierdzenia CAP” Cassandra działa na Modelu AP, podczas gdy HBase to Model CP.
Twierdzenie CAP
Twierdzenie to stosuje się w systemach rozproszonych. C oznacza spójność, A oznacza dostępność, a P oznacza tolerancję partycji. Twierdzenie CAP wyjaśnione poniżej:
C (Spójność): Spójność oznacza, że jeśli ktoś zapisał wartość w bazie danych, inni mogą natychmiast odczytać tę samą wartość.
A (Dostępność) : Dostępność oznacza, że jeśli niektóre węzły nie są dostępne w klastrze (Węzły uległy awarii / nie działają w klastrze z powodu pewnych problemów) nie będą miały wpływu na cały klaster, a system rozproszony / baza danych będą dostępne w celu uzyskania dostępu do danych. Klaster będzie dostępny do wszelkiego rodzaju zadań.
P (Tolerancja partycji): Tolerancja partycji oznacza, że jedno centrum danych ulegnie awarii, co nie powinno mieć wpływu na dane w węzłach, a wszystkie dane powinny być dostępne w dowolnym momencie. Oznacza to, że tolerancja partycji pozwala na lepszą replikację danych do innych Data Center, a także w środowisku klastrowym.
Tabela porównawcza HBase vs Cassandra
| Zwrotnica | HBase | Cassandra |
| Twierdzenie CAP | Spójność i dostępność | Dostępność i tolerancja partycji |
| Koprocesor | tak | Nie |
| Przywracanie równowagi | HBase zapewnia automatyczne równoważenie w ramach klastra. | Cassandra zapewnia również równoważenie, ale nie dla całego klastra |
| Model architektury | Opiera się na modelu architektury Master-Slave | Cassandra oparta jest na Active-Active Node Modal |
| Baza danych | Opiera się na Google BigTable | Cassandra jest oparta na Amazon DynamoDB |
| SPoF (pojedynczy punkt awarii) | Jeśli węzeł główny nie jest dostępny, cały klaster nie będzie dostępny | Wszystkie węzły mają tę samą rolę w klastrze, więc nie ma SPoF |
| DR (odzyskiwanie po awarii) | DR jest możliwe, jeśli skonfigurowano dwa węzły główne. | Tak, ponieważ wszystkie węzły mają tę samą rolę |
| Zgodność z HDFS | Tak, ponieważ HBase przechowuje wszystkie metadane w HDFS | Nie |
| Konsystencja | Silny | Nie silny jak HBase |
Wniosek - HBase vs Cassandra
Facebook i inna strona sieci społecznościowych wolą HBase (wcześniej obie korzystały z Cassandry, patrz post na Facebooku) ze względu na swoją dostępność inny sektor domeny bankowej szuka bezpieczeństwa dla każdej transakcji finansowej, więc wybiorą Cassandrę zamiast HBase.
Kluczowe cechy Cassandra obejmują wysoką dostępność, minimalne administrowanie i brak SPoF (pojedynczego punktu awarii) z drugiej strony HBase jest dobry do szybszego odczytu i zapisu danych z liniową skalowalnością.
Firmy takie jak Verizon, Bloomberg, Bank of America i wiele innych korzystają z HBase, a Cassandra jest używana przez główne serwisy społecznościowe, takie jak Twitter, Facebook itp.
Nie możemy stwierdzić, który z nich jest najlepszy, zarówno HBase, jak i Cassandra mają swoje zalety i wady. Rzeczywistą wydajność baz danych HBase i Cassandra można zobaczyć w środowisku produkcyjnym.
Polecane artykuły:
Jest to przewodnik po HBase vs Cassandra, ich znaczeniu, porównaniu bezpośrednim, kluczowych różnicach, tabeli porównawczej i wnioskach. Możesz także przejrzeć następujące artykuły, aby dowiedzieć się więcej -
- Hadoop vs Apache Spark - ciekawe rzeczy, które musisz wiedzieć
- Jak złamać wywiad programisty Hadoop?
- Top 5 trendów Big Data
- 5 wyzwań analityki Big Data