
Wprowadzenie do architektury gałęzi
Architektura gałęzi zbudowana jest na ekosystemie Hadoop. Hive często wchodzi w interakcje z Hadoop. Apache Hive radzi sobie zarówno z systemem baz danych SQL domeny, jak i redukcją map. Aplikacje gałęzi można pisać w różnych językach, takich jak Java, Python. Architektura gałęzi pokazuje, jak napisać język zapytań gałęzi i jak interakcje między programistą są wykonywane przy użyciu interfejsu wiersza poleceń. Język zapytań Hive wykonuje konwersję wszystkich zadań klastra Hadoop poprzez redukcję map. Jak wszyscy wiemy, Hadoop przetwarza duże zbiory danych w środowisku rozproszonym i tworzy platformę open source. Dzięki gałęzi można elastycznie zarządzać zapytaniami i wykonywać je, a także wspierać osoby wykonujące funkcje takie jak enkapsulacja, zapytania ad-hoc. W tym artykule przedstawiono krótkie wprowadzenie do architektury gałęzi znajdującej się w warstwie Hadoop w celu przeprowadzenia podsumowania w dużych zbiorach danych.
Architektura gałęzi z jej komponentami
Hive odgrywa ważną rolę w analizie danych i integracji analizy biznesowej i obsługuje formaty plików, takie jak plik tekstowy, plik rc. Hive używa rozproszonego systemu do przetwarzania i wykonywania zapytań, a przechowywanie jest ostatecznie wykonywane na dysku i przetwarzane przy użyciu frameworka zmniejszającego mapę. Rozwiązuje problem optymalizacji znaleziony w obszarze zmniejszania mapy i wykonywania zadań wsadowych, które są jasno wyjaśnione w przepływie pracy. Tutaj sklep meta przechowuje informacje o schemacie. Framework o nazwie Apache Tez jest zaprojektowany do wykonywania zapytań w czasie rzeczywistym.
Główne elementy ula podano poniżej:
- Klienci Hive
- Usługi Hive
- Przechowywanie ula (przechowywanie meta)
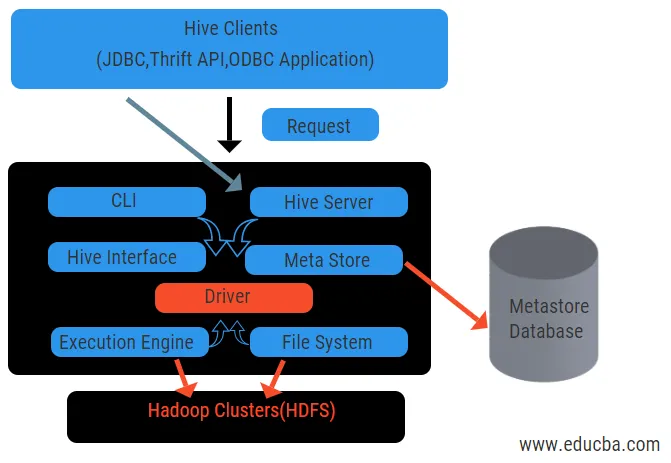
Powyższy schemat pokazuje architekturę gałęzi i jej elementów składowych.
Klienci Hive:
Obejmują one aplikację Thrift do wykonywania łatwych poleceń gałęzi, które są dostępne dla Pythona, Ruby, C ++ i sterowników. Te korzyści aplikacji klienckiej do wykonywania zapytań w gałęzi. Hive ma trzy typy kategoryzacji klientów: klienci oszczędności, klienci JDBC i ODBC.
Usługi Hive:
Aby przetworzyć wszystkie zapytania hive ma różne usługi. Wszystkie funkcje są łatwo zdefiniowane przez użytkownika w ulu. Zobaczmy w skrócie wszystkie te usługi:
- Interfejs wiersza poleceń ( interfejs użytkownika): Umożliwia interakcję między użytkownikiem a gałęzią, domyślną powłoką. Zapewnia GUI do wykonywania wiersza polecenia gałęzi i wglądu gałęzi. Możemy również używać interfejsów internetowych (HWI) do przesyłania zapytań i interakcji z przeglądarką internetową.
- Sterownik gałęzi : odbiera zapytania z różnych źródeł i klientów, takich jak serwer oszczędzania, i przechowuje i pobiera sterowniki ODBC i JDBC, które są automatycznie łączone z gałęzią. Ten komponent dokonuje analizy semantycznej po zobaczeniu tabel z metastore, który analizuje zapytanie. Sterownik korzysta z pomocy kompilatora i wykonuje funkcje takie jak analizator składni, Planner, Wykonywanie zadań MapReduce i optymalizator.
- Kompilator: parsowanie i proces semantyczny zapytania odbywa się przez kompilator. Konwertuje zapytanie na abstrakcyjne drzewo składniowe i ponownie w DAG w celu zapewnienia zgodności. Z kolei optymalizator dzieli dostępne zadania. Zadaniem modułu wykonującego jest uruchomienie zadań i monitorowanie harmonogramu potoku zadań.
- Mechanizm wykonawczy: wszystkie zapytania są przetwarzane przez silnik wykonawczy. Plany etapów DAG są wykonywane przez silnik i pomagają w zarządzaniu zależnościami między dostępnymi etapami i wykonywaniu ich na odpowiednim elemencie.
- Metastore: Działa jako centralne repozytorium do przechowywania wszystkich ustrukturyzowanych informacji metadanych, a także jest ważnym aspektem dla gałęzi, ponieważ zawiera informacje takie jak tabele i szczegóły partycjonowania oraz przechowywanie plików HDFS. Innymi słowy, powiemy, że metastore działa jako przestrzeń nazw dla tabel. Metastore jest uważany za oddzielną bazę danych, która jest współdzielona także przez inne komponenty. Metastore ma dwa elementy zwane usługą i pamięcią zaległości.
Model danych gałęzi jest podzielony na partycje, segmenty, tabele. Wszystkie te można filtrować, mieć klucze partycji i oceniać zapytanie. Zapytanie Hive działa w ramach platformy Hadoop, a nie w tradycyjnej bazie danych. Serwer gałęzi jest interfejsem między zdalnymi zapytaniami klienckimi do gałęzi. Silnik wykonawczy jest całkowicie osadzony w serwerze gałęzi. Możesz znaleźć aplikację ula w uczeniu maszynowym, inteligencję biznesową w procesie wykrywania.
Przepływ pracy ula:
Hive działa w dwóch rodzajach trybów: tryb interaktywny i tryb nieinteraktywny. Poprzedni tryb pozwala wszystkim poleceniom gałęzi przejść bezpośrednio do powłoki gałęzi, podczas gdy późniejszy typ wykonuje kod w trybie konsoli. Dane są dzielone na partycje, które dalej dzielą się na segmenty. Plany wykonania opierają się na agregacji i wypaczeniu danych. Dodatkową zaletą używania gałęzi jest to, że z łatwością przetwarza dużą skalę informacji i ma więcej interfejsów użytkownika.
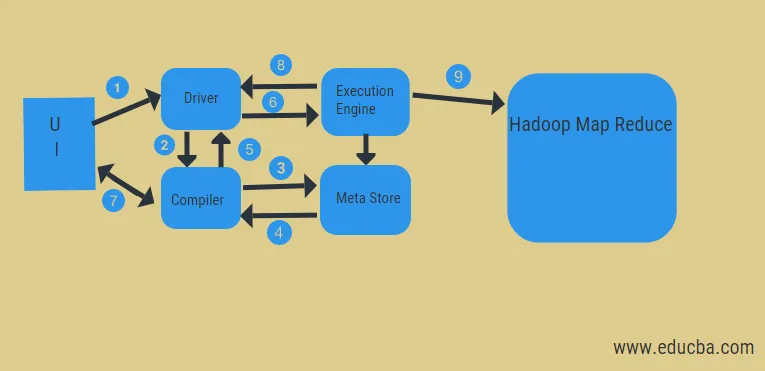
Z powyższego diagramu możemy zobaczyć przepływ danych w ulu za pomocą systemu Hadoop.
Kroki obejmują:
- wykonać zapytanie z interfejsu użytkownika
- uzyskać plan z zadań kierowcy etapów DAG
- pobierz żądanie metadanych ze sklepu meta
- wyślij metadane z kompilatora
- odesłanie planu do kierowcy
- Wykonaj plan w silniku wykonawczym
- pobieranie wyników dla odpowiedniego zapytania użytkownika
- wysyłanie wyników dwukierunkowo
- silnik przetwarzania przetwarzania w HDFS z mapowaniem i pobieraniem wyników z węzłów danych utworzonych przez moduł śledzenia zadań. Działa jak łącznik między gałęzią a Hadoopem.
Zadaniem silnika wykonawczego jest komunikacja z węzłami w celu uzyskania informacji przechowywanych w tabeli. Tutaj wykonywane są operacje SQL, takie jak tworzenie, upuszczanie, zmiana w celu uzyskania dostępu do tabeli.
Wniosek:
Przeszliśmy przez architekturę Hive i ich przepływ pracy, ul zasadniczo wykonuje petabajt danych, a zatem jest to pakiet hurtowni danych na platformie Hadoop. Ponieważ ula jest dobrym wyborem do obsługi dużej ilości danych, pomaga w przygotowaniu danych z przewodnikiem interfejsu SQL w celu rozwiązania problemów MapReduce. Rój Apache to narzędzie ETL do przetwarzania danych strukturalnych. Znajomość zasad działania architektury ulu pomaga pracownikom korporacyjnym zrozumieć zasadę działania ula i ma dobry początek w programowaniu gałęzi.
Polecane artykuły:
To był przewodnik po architekturze ula. Tutaj omawiamy architekturę gałęzi, różne komponenty i przepływ pracy gałęzi. możesz również zapoznać się z następującymi artykułami, aby dowiedzieć się więcej-
- Architektura Hadoop
- Zastosowania Rubiego
- Co to jest C ++
- Co to jest baza danych MySQL
- Hive Order By