

Wywiad dogłębny Wywiady Pytania i odpowiedzi
Dzisiaj głębokie uczenie się postrzegane jest jako jedna z najszybciej rozwijających się technologii z ogromną zdolnością do opracowania aplikacji, która kiedyś była trudna. Rozpoznawanie mowy, rozpoznawanie obrazów, znajdowanie wzorców w zbiorze danych, klasyfikacja obiektów na zdjęciach, generowanie tekstu znaków, samodzielne prowadzenie samochodów i wiele innych to tylko kilka przykładów, w których Deep Learning wykazało swoje znaczenie.
W końcu znalazłeś swoją wymarzoną pracę w głębokim uczeniu się, ale zastanawiasz się, jak złamać wywiad głębokiego uczenia się i jakie mogą być prawdopodobne pytania dotyczące głębokiego uczenia się. Każda rozmowa kwalifikacyjna jest inna, a zakres pracy również inny. Mając to na uwadze, opracowaliśmy najczęstsze pytania i odpowiedzi podczas głębokiego uczenia się, aby pomóc Ci odnieść sukces w rozmowie.
Poniżej znajduje się kilka pytań do głębokiego uczenia się, które często zadawane są podczas wywiadu i które mogłyby również pomóc w sprawdzeniu twoich poziomów:
Część 1 - Pytania do pogłębionego uczenia się (podstawowe)
Ta pierwsza część obejmuje podstawowe pytania i odpowiedzi podczas pogłębionego uczenia się
1. Co to jest głębokie uczenie się?
Odpowiedź:
Obszar uczenia maszynowego, który koncentruje się na głębokich sztucznych sieciach neuronowych, które są luźno inspirowane mózgami. Alexey Grigorevich Ivakhnenko opublikował pierwszego generała o działającej sieci Deep Learning. Dziś ma zastosowanie w różnych dziedzinach, takich jak widzenie komputerowe, rozpoznawanie mowy, przetwarzanie języka naturalnego.
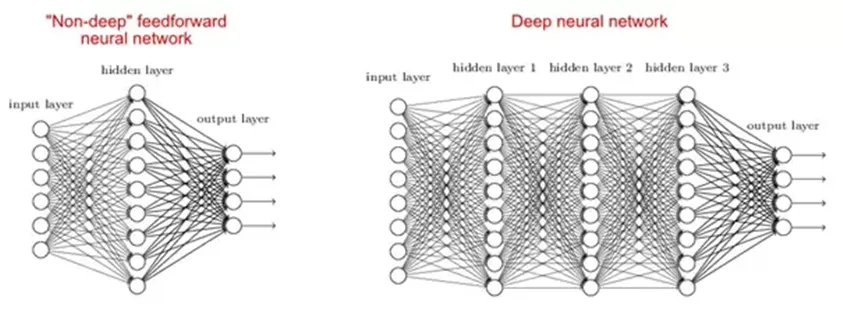
2. Dlaczego sieci głębokie są lepsze od płytkich?
Odpowiedź:
Istnieją badania, które mówią, że zarówno płytkie, jak i głębokie sieci mogą pasować do dowolnej funkcji, ale ponieważ sieci głębokie mają kilka ukrytych warstw, często różnych typów, są w stanie budować lub wydobywać lepsze funkcje niż modele płytkie o mniejszej liczbie parametrów.
3. Jaka jest funkcja kosztów?
Odpowiedź:
Funkcja kosztu jest miarą dokładności sieci neuronowej w odniesieniu do danej próbki szkoleniowej i oczekiwanej wydajności. Jest to pojedyncza wartość, nievector, ponieważ zapewnia wydajność sieci neuronowej jako całości. Można go obliczyć w następujący sposób: Średnia błąd kwadratowy:
MSE = 1n∑i = 0n (Y i – Yi) 2
Gdzie Y i pożądana wartość Y jest tym, co chcemy zminimalizować.
Przejdźmy do następnych pytań do głębokiego uczenia się.
4. Co to jest zniżanie gradientowe?
Odpowiedź:
Zejście gradientu jest w zasadzie algorytmem optymalizacji, który służy do poznania wartości parametrów minimalizujących funkcję kosztów. Jest to algorytm iteracyjny, który porusza się w kierunku najbardziej stromego zejścia określonego przez ujemną wartość gradientu. Obliczamy spadek gradientu funkcji kosztu dla danego parametru i aktualizujemy parametr według poniższego wzoru: -
Θ: = Θ – αd∂ΘJ (Θ)
Gdzie Θ - jest wektorem parametrów, α - szybkość uczenia się, J (Θ) - jest funkcją kosztu.
5. Co to jest propagacja wsteczna?
Odpowiedź:
Backpropagation jest algorytmem szkoleniowym stosowanym w wielowarstwowej sieci neuronowej. W tej metodzie przenosimy błąd z końca sieci do wszystkich wag wewnątrz sieci, umożliwiając w ten sposób wydajne obliczanie gradientu. Można go podzielić na kilka kroków w następujący sposób:
OrPoprzednia propagacja danych treningowych w celu wygenerowania wyników.
Using Następnie można obliczyć pochodną błędu wartości wyjściowej i wyjściowej w odniesieniu do aktywacji wyjścia.
Hen Następnie cofamy się do obliczenia pochodnej błędu w odniesieniu do aktywacji wyjścia poprzedniej i kontynuujemy to dla wszystkich ukrytych warstw.
Korzystając z wcześniej obliczonych pochodnych dla danych wyjściowych i wszystkich ukrytych warstw, obliczamy pochodne błędów w odniesieniu do wag.
Następnie aktualizujemy wagi.
6. Wyjaśnij następujące trzy warianty opadania gradientu: okresowy, stochastyczny i mini-okresowy?
Odpowiedź:
Stochastyczne zejście gradientu : Używamy tylko jednego przykładu treningu do obliczania parametrów gradientu i aktualizacji.
Batch Gradient Descent : Tutaj obliczamy gradient dla całego zestawu danych i wykonujemy aktualizację przy każdej iteracji.
Mini-wsadowe zejście gradientu : Jest to jeden z najpopularniejszych algorytmów optymalizacji. Jest to wariant Stochastycznego Zejścia Gradientu i tutaj zamiast jednego przykładu treningowego stosuje się mini-partię próbek.
Część 2 - pytania do wywiadu dogłębnego uczenia się (zaawansowane)
Przyjrzyjmy się teraz zaawansowanym pytaniom podczas głębokiego uczenia się.
7. Jakie są korzyści z opadania gradientem mini-partii?
Odpowiedź:
Poniżej przedstawiamy zalety opadania gradientem w mini partii
• Jest to bardziej wydajne w porównaniu do stochastycznego spadku.
• Uogólnienie poprzez znalezienie płaskich minimów.
• Mini-partie pozwalają na przybliżenie gradientu całego zestawu treningowego, co pomaga nam uniknąć lokalnych minimów.
8. Co to jest normalizacja danych i dlaczego jej potrzebujemy?
Odpowiedź:
Podczas propagacji wstecznej stosowana jest normalizacja danych. Głównym motywem normalizacji danych jest zmniejszenie lub wyeliminowanie nadmiarowości danych. Tutaj przeskalowujemy wartości, aby dopasować je do określonego zakresu, aby osiągnąć lepszą zbieżność.
Przejdźmy do następnych pytań do głębokiego uczenia się.
9. Co to jest inicjalizacja wagi w sieciach neuronowych?
Odpowiedź:
Inicjalizacja wagi jest jednym z bardzo ważnych kroków. Zła inicjalizacja wagi może uniemożliwić uczenie się sieci, ale dobra inicjalizacja wagi pomaga w szybszej konwergencji i lepszym ogólnym błędzie. Białości można ogólnie inicjalizować na zero. Reguła ustalania ciężarów powinna być bliska zeru, ale nie być zbyt mała.
10. Co to jest auto-koder?
Odpowiedź:
Autokoder jest autonomicznym algorytmem uczenia maszynowego, który wykorzystuje zasadę propagacji wstecznej, w której wartości docelowe są ustawione na równe podanym wejściom. Wewnętrznie ma ukrytą warstwę, która opisuje kod używany do reprezentowania danych wejściowych.
Niektóre kluczowe fakty na temat autoencodera są następujące: -
• Jest to nienadzorowany algorytm ML podobny do analizy głównych składników
• Minimalizuje tę samą funkcję celu, co analiza głównych składników
• Jest to sieć neuronowa
• Docelowym wyjściem sieci neuronowej jest wejście
11. Czy podłączenie wyjścia z warstwy 4 z powrotem do wejścia warstwy 2 jest w porządku?
Odpowiedź:
Tak, można to zrobić, biorąc pod uwagę, że wyjście warstwy 4 pochodzi z poprzedniego kroku czasowego, jak w RNN. Musimy również założyć, że poprzednia partia wejściowa jest czasem skorelowana z bieżącą partią.
Przejdźmy do następnych pytań do głębokiego uczenia się.
12. Co to jest maszyna Boltzmanna?
Odpowiedź:
Maszyna Boltzmann służy do optymalizacji rozwiązania problemu. Praca maszyny Boltzmann polega zasadniczo na optymalizacji ciężarów i ilości dla danego problemu.
Kilka ważnych punktów na temat maszyny Boltzmann -
• Wykorzystuje powtarzającą się strukturę.
• Składa się z neuronów stochastycznych, które składają się z jednego z dwóch możliwych stanów, 1 lub 0.
• Neurony w tym są w stanie adaptacyjnym (stan wolny) lub zaciśniętym (stan zamrożony).
• Jeśli zastosujemy symulowane wyżarzanie w dyskretnej sieci Hopfield, wówczas stanie się maszyną Boltzmanna.
13. Jaka jest rola funkcji aktywacyjnej?
Odpowiedź:
Funkcja aktywacji służy do wprowadzenia nieliniowości do sieci neuronowej, pomagając jej nauczyć się bardziej złożonych funkcji. Bez którego sieć neuronowa byłaby w stanie nauczyć się tylko funkcji liniowej, która jest liniową kombinacją jej danych wejściowych.
Polecane artykuły
Jest to przewodnik po liście pytań i odpowiedzi w trakcie głębokiego uczenia się, dzięki czemu kandydat może łatwo zlikwidować te pytania. Możesz także przejrzeć poniższe artykuły, aby dowiedzieć się więcej
- Poznaj 10 najbardziej przydatnych pytań do wywiadu HBase
- Przydatne uczenie maszynowe Wywiad Pytania i odpowiedzi
- Top 5 najcenniejszych pytań do wywiadu z zakresu nauki o danych
- Ważne pytania i odpowiedzi na wywiad z Ruby