

Co to jest Kafka?
Aby zrozumieć Kafkę, lepiej zrozumieć, czym jest technologia „przetwarzania strumieniowego”. „Przetwarzanie strumieniowe to technologia, w której użytkownik może przesyłać zapytania do ciągłego strumienia danych w mikroprzedziale czasowym, aby lepiej zrozumieć odpowiedzialne za nie warunki.
Scenariusz w czasie rzeczywistym - wyobraź sobie, że czujnik temperatury wysyła dane, które możesz zapytać i otrzymać alert po otrzymaniu punktu zamarzania. To zapytanie danych można wykonać w mikrosekundach.
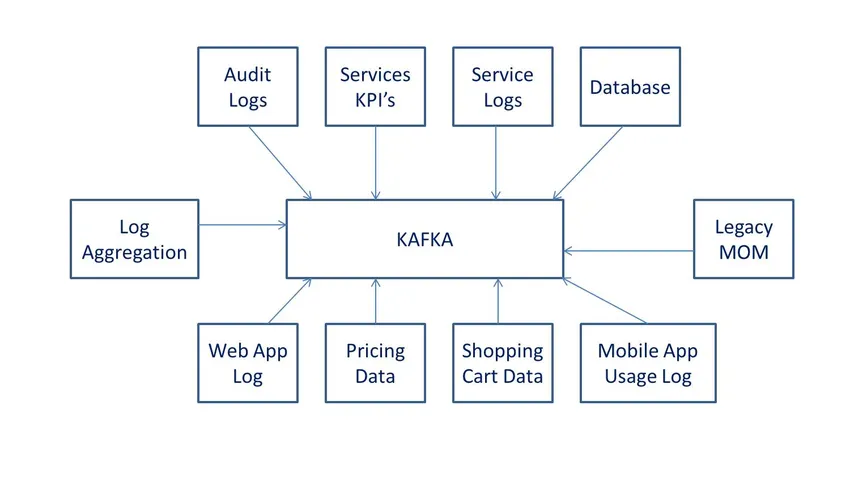
Definicje
według Wiki jest to oprogramowanie do przetwarzania danych typu open source. Został opracowany przez LinkedIn, a później przekazany na oprogramowanie Apache.
Zrozumieć Kafkę
Jego wzrost eksploduje wykładniczo. Zobaczmy kilka faktów i statystyk, aby lepiej podkreślić naszą myśl. Korzysta z najlepszych preferencji ponad jednej trzeciej Fortune 500 na całym świecie. Ta dystrybucja jest dzielona przez firmy turystyczne, gigantów telekomunikacyjnych, banki i kilka innych. LinkedIn, Microsoft i Netflix przetwarzają cztery przecinki dziennie z Kafką (prawie równa 1 000 000 000 000).
Służy do strumieni danych w czasie rzeczywistym, do zbierania dużych danych lub do analizy w czasie rzeczywistym (lub obu). Kafka jest używana z mikrousługami w pamięci w celu zapewnienia trwałości i może być używana do dostarczania zdarzeń do CEP (złożone systemy przesyłania strumieniowego zdarzeń) i systemów automatyzacji w stylu IoT / IFTTT.
Jak działa Kafka tak łatwo?
Kierowanie się prostotą byłoby właściwym sposobem na określenie wydajności. Łatwo zorientować się, jak działa Kafka z taką łatwością z jego konfiguracji i użytkowania. Ta zwiększona wydajność zachowania jest poświęcona jego stabilności, zapewnieniu niezawodnej trwałości, a także elastycznej wbudowanej możliwości publikowania, subskrybowania lub utrzymywania w kolejce. Jest to bardzo ważne, jeśli musisz poradzić sobie z grupą N-liczby klientów, jeśli chcesz pokazać solidną replikację na rynku, aby zapewnić swoim klientom spójne podejście (tj. Partycję tematyczną Kafka). Jednym z kluczowych zachowań Kafki, które odróżniają go od konkurentów, jest jego kompatybilność z systemami ze strumieniami danych - jego proces i umożliwia tym systemom agregowanie, przekształcanie i ładowanie innych sklepów dla wygody pracy. „Wszystkie powyższe fakty nie byłyby możliwe, gdyby Kafka był powolny”. Dzięki wyjątkowej wydajności jest to możliwe.
Dodatkowym ułatwieniem pracy Kafki jest przejście do „poziomu systemu operacyjnego”. Zobaczmy, jak działa Kafka na poziomie systemu operacyjnego -
- Opiera się na jądrach systemu operacyjnego w celu szybszego przenoszenia danych i działa na zasadzie zerowej kopii.
- Pozwala na grupowanie rekordów danych w części, które są widoczne dla użytkowników w systemie plików (zwanym także dziennikiem tematycznym Kafka).
- Funkcja grupowania danych zapewnia wydajną kompresję danych z redukcją opóźnień we / wy.
- Ma możliwość skalowania w poziomie za pomocą dzielenia na fragmenty. Może podzielić dziennik tytułów na setki partycji na tysiące. Umożliwia to łatwe radzenie sobie z ogromnym obciążeniem.
Co możesz zrobić z Kafką?
Jeśli Twoja firma regularnie korzysta z ogromnych zestawów danych, potrzebujesz Kafki. Istnieje długa lista firm, które z niej korzystają.
- LinkedIn używa do śledzenia danych i wskaźników operacyjnych.
- Twitter w celu zapewnienia infrastruktury przetwarzania strumieniowego.
Istnieje długa lista firm od Uber do Spotify i Goldman Sachs do Cisco.
Zalety
- Wysoka przepustowość: może z łatwością obsługiwać dużą ilość danych, gdy generowanie z dużą prędkością jest wyjątkową zaletą na korzyść Kafki. Ta aplikacja nie ma ogromnego sprzętu. Dzięki zdolności do obsługi przepustowości wiadomości z częstotliwością tysięcy wiadomości na sekundę.
- Małe opóźnienie: Obsługa niskiego opóźnienia przy generowaniu wiadomości o dużej objętości.
- Odporność na awarie: Ta funkcja jest bardzo przydatna, ma nieodłączną funkcję ograniczania przez węzeł wbudowany w klaster.
- Trwałość: jest bardzo trwała w działaniu i dlatego wiele MNC woli używać Kafki. Mówiąc o trwałości w operacjach, wiadomości nie mogą się zgubić w perspektywie długoterminowej.
Wymagane umiejętności
Nie ma specjalnych wymagań, aby być profesjonalistą Kafka. Podkreśliliśmy jednak niektóre strumienie i specjalistów -
- Programiści, którzy chętnie chcą zrobić karierę w strumieniu Big Data i chcą tam przyspieszyć karierę.
- Specjaliści zajmujący się testowaniem mają dobry zakres w Kafce pod względem systemów kolejkowania i przesyłania wiadomości
- Architekci - ponieważ wszystko potrzebuje trochę frameworka, a framework ten może być od czasu do czasu aktualizowany. Architekci Big Data uznaliby Kafkę za dobrą inwestycję zawodową.
- Kierownik projektu jest potrzebny, jeśli powyższy specjalista jest w celu lepszego zarządzania zasobami. Tak więc wyższe stanowiska są również dostępne dla specjalistów ds. Zarządzania w dziedzinie Kafki.
Dlaczego warto korzystać z Kafka?
W celu śledzenia danych i manipulowania nimi zgodnie z potrzebami biznesowymi Kafka jest preferowana na całym świecie. Daje to możliwość strumieniowego przesyłania danych w czasie rzeczywistym dzięki analizom w czasie rzeczywistym. Jest szybki, skalowalny i trwały oraz zaprojektowany jako odporny na uszkodzenia. Istnieje wiele przypadków użycia w Internecie, w których można zobaczyć, dlaczego JMS, RabbitMQ i AMQP nie są nawet uważane za współpracujące, ponieważ potrzeba jest obsługiwać dużą objętość i szybkość reakcji.
Ma wysoką przepustowość, niezawodną konfigurację z charakterystyką replikacji, co czyni go preferowanym wyborem do pracy z czujnikami IoT.
Kompatybilność to kolejny powód, aby używać go i sprawić, że będzie akceptowalny na całym świecie. Można go łatwo skonfigurować do pracy z poniższą aplikacją. Ta kombinacja jest bardzo ważna dla wielu firm, aby rozwijać działalność i przetrwać (ponieważ oszczędza czas i pieniądze).
- Flume
- Spark Streaming
- HBase
- Spark do pobierania, przetwarzania i analizy danych w czasie rzeczywistym.
- Służy do karmienia BigData Hadoop
Zakres
Świetnie sobie radzi na całym świecie. Nie mówimy tego raczej o statystykach. Spójrzmy -
Statystyki wynagrodzeń dla specjalistów Kafka - PayScale
- Inżynier oprogramowania - 109 825 USD
- Inżynier danych - 109 580 USD
- Deweloperzy - 81.182 USD
- Starszy inżynier danych - 127 836 USD
Wniosek
Obecnie Kafka stał się de facto standardem w zakresie analizy danych w czasie rzeczywistym z najwyższą precyzją w mikrosekundach. Przedstawiliśmy nasze spostrzeżenia w zakresie danych i szczegółów wspierających technologie Kafka. Istnieje kilka dużych firm, które codziennie wykorzystują dane, dlatego potrzebują specjalistów, aby wykorzystać te ogromne zbiory danych. Dzięki Kafce możesz być pewien, że poprowadzi swoją karierę w analityce BigData
Polecane artykuły
To był przewodnik po tym, co jest Kafka. Tutaj omówiliśmy działanie, zakres, rozwój kariery i zalety Kafki. Możesz także przejrzeć nasze inne sugerowane artykuły, aby dowiedzieć się więcej -
- Co to jest Apache?
- Co to jest Big data i Hadoop?
- Co to jest Azure?
- Co to jest technologia Big Data?
- Kafka vs Spark | 5 najważniejszych różnic
- Przegląd i najważniejsze zastosowania Kafki
- Kafka vs Kinesis | 5 różnic w infografikach