
Wprowadzenie do nauki o danych
Data Science to jedno z najszybciej rozwijających się, wymagających i najlepiej płatnych miejsc pracy w tej dekadzie. Pytanie brzmi: czym jest nauka o danych? nauka danych jest dziedziną interdyscyplinarną (składa się z więcej niż jednej gałęzi badań), która wykorzystuje statystyki, informatykę i algorytmy uczenia maszynowego w celu uzyskania wglądu zarówno w dane ustrukturyzowane, jak i nieustrukturyzowane. Według „Economic Times” w Indiach odnotowano ponad 400-procentowy wzrost popytu na specjalistów ds. Analizy danych w różnych sektorach przemysłu w czasie, gdy podaż takich talentów świadczy o powolnym wzroście.
Główne elementy Data Science
Główne elementy lub proces zastosowane we wstępie do nauki o danych są następujące:
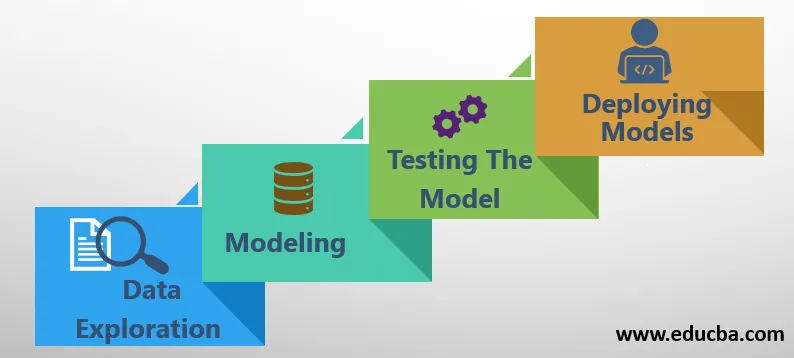
1. Eksploracja danych
Jest to najważniejszy krok, ponieważ ten etap zajmuje najwięcej czasu. Około 70 procent czasu poświęcane jest na eksplorację danych. Głównym składnikiem nauki o danych są dane, więc kiedy otrzymujemy dane, rzadko kiedy mają one poprawną strukturę. W danych jest dużo hałasu. Szum oznacza tutaj wiele niepożądanych danych, które nie są wymagane. Więc co robimy na tym etapie? Ten krok obejmuje próbkowanie i przekształcanie danych, w których sprawdzamy obserwacje (wiersze) i cechy (kolumny) i usuwamy szum za pomocą metod statystycznych. Ten krok służy również do sprawdzenia zależności między różnymi funkcjami (kolumnami) w zestawie danych. Przez relację rozumiemy, czy funkcje (kolumny) są od siebie zależne, czy niezależne od siebie, czy w danych brakuje wartości albo nie. Zasadniczo dane są przekształcane i przygotowywane do dalszego wykorzystania. Dlatego jest to jeden z najbardziej czasochłonnych kroków.
2. Modelowanie
Tak więc do tej pory nasze dane są przygotowane i gotowe do pracy. To drugi krok, w którym faktycznie używamy algorytmów uczenia maszynowego. Tutaj faktycznie dopasowujemy dane do modelu. Wybór modelu zależy od rodzaju danych, jakie posiadamy i wymagań biznesowych. Na przykład wybór modelu do polecania artykułu klientowi będzie inny niż model wymagany do przewidywania liczby artykułów, które zostaną sprzedane w danym dniu. Po podjęciu decyzji o modelu dopasowujemy dane do modelu.
3. Testowanie modelu
Jest to kolejny krok i bardzo ważny w odniesieniu do wydajności modelu. Model jest testowany z danymi testowymi, aby sprawdzić dokładność i inne cechy modelu oraz wprowadzić wymagane zmiany w modelu, aby uzyskać pożądany wynik. Jeśli nie uzyskamy pożądanej dokładności, możemy ponownie przejść do kroku 2 (modelowanie), wybrać inny model, a następnie powtórzyć ten sam krok 3 i wybrać model, który daje najlepszy wynik zgodnie z wymaganiami biznesowymi.
4. Wdrażanie modeli
Gdy uzyskamy pożądany wynik poprzez odpowiednie testowanie zgodnie z wymaganiami biznesowymi, finalizujemy model, który daje nam najlepszy wynik pod względem wyników testowych i wdrażamy model w środowisku produkcyjnym.
Charakterystyka Data Science
Dane badacza są następujące:
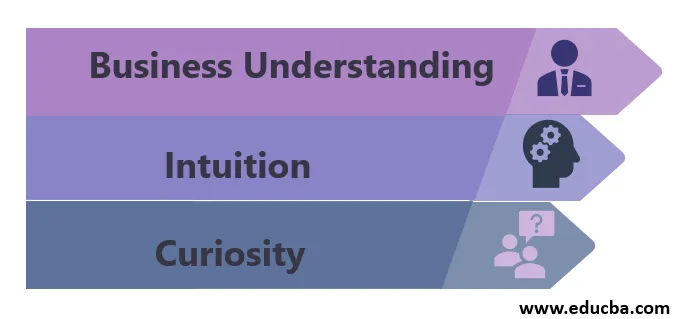
1. Zrozumienie biznesu
Jest to najważniejsza cecha, ponieważ jeśli nie rozumiesz firmy, nie możesz stworzyć dobrego modelu, nawet jeśli masz dobrą znajomość algorytmów uczenia maszynowego lub umiejętności statystycznych. Naukowiec danych musi zrozumieć wymagania biznesowe i opracować odpowiednie analizy. Tak więc znajomość domeny biznesu staje się ważna lub pomocna.
2. Intuicja
Chociaż zaangażowana matematyka jest sprawdzona i fundamentalna, naukowiec danych musi wybrać odpowiedni model z odpowiednią dokładnością. Ponieważ wszystkie modele nie dają dokładnie takich samych wyników. Dlatego naukowiec danych musi wyczuć, kiedy model jest gotowy do wdrożenia produkcyjnego. Potrzebują też intuicji, aby wiedzieć, w którym momencie model produkcyjny jest przestarzały i wymaga refaktoryzacji, aby reagować na zmieniające się środowisko biznesowe.
3. Ciekawość
Data Science nie jest nową dziedziną. Był już tam wcześniej, ale postęp w tej dziedzinie jest bardzo szybki, a nowe metody rozwiązywania znanych problemów są opracowywane w sposób ciągły, ponieważ zainteresowanie naukowców danymi do nauki nowych technologii staje się bardzo ważne.
Aplikacje
Tutaj, we wstępie do nauki o danych, wyjaśniliśmy, że zastosowania nauki o danych są ogromne. Jest wymagany w każdej dziedzinie. Oto przykłady kilku sektorów, w których nauka danych może być wykorzystywana lub wykorzystywana aktywnie.
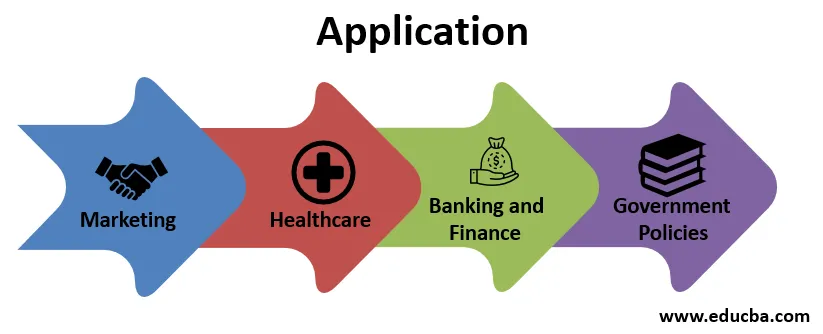
1. Marketing
Marketing ma szeroki zakres, na przykład strategia ulepszonej wyceny Firmy takie jak Uber, firmy e-commerce mogą stosować wyceny oparte na danych naukowych, co pozwala im zwiększać zyski.
2. Opieka zdrowotna
Używanie danych do noszenia w celu zapobiegania problemom zdrowotnym i monitorowania ich. Dane generowane z organizmu mogą być wykorzystywane w służbie zdrowia, aby zapobiegać przyszłym wypadkom.
3. Bankowość i finanse
W trakcie omawiania wprowadzenia do nauki o danych teraz zajmiemy się zastosowaniem zastosowań nauki danych w sektorze bankowym do wykrywania oszustw, które mogą być pomocne w ograniczaniu aktywów zagrożonych banków.
4. Polityka rządu
Rząd może wykorzystać analizę danych w celu opracowania lepszych polityk w celu lepszego zaspokojenia potrzeb ludzi i tego, czego chcą, korzystając z danych, które mogą uzyskać, przeprowadzając ankiety i inne z innych oficjalnych źródeł.
Zalety i wady Data Science
Po przejrzeniu wszystkich składników, cech i szerokiego wprowadzenia do Data Science, zamierzamy zbadać zalety i wady Data Science:
Zalety
W tym temacie Wprowadzenie do Data Science pokazujemy również zalety Data Science. Niektóre z nich są następujące:
- Pomaga nam uzyskać wgląd w dane historyczne za pomocą jego potężnych narzędzi.
- Pomaga zoptymalizować firmę, zatrudnić odpowiednie osoby i wygenerować większy przychód, ponieważ korzystanie z analizy danych pomaga w podejmowaniu lepszych decyzji biznesowych w przyszłości.
- Firmy mogą lepiej rozwijać i sprzedawać swoje produkty, ponieważ mogą lepiej wybierać docelowych klientów.
- Wprowadzenie do Data Science pomaga również konsumentom w wyszukiwaniu lepszych towarów, szczególnie w witrynach e-commerce opartych na systemie rekomendacji opartym na danych.
Niedogodności
Kiedy studiowaliśmy wprowadzenie do nauki o danych, teraz idziemy do przodu z wadami nauki o danych:
Wady występują zwykle, gdy analizy danych są wykorzystywane do profilowania klientów i naruszania ich prywatności, ponieważ ich informacje, takie jak transakcje, zakupy i subskrypcje, są widoczne dla ich firm macierzystych. Informacje uzyskane za pomocą analizy danych mogą być wykorzystane przeciwko określonej grupie, osobie, krajowi lub społeczności.
Polecane artykuły
To był przewodnik po wprowadzeniu do Data Science. Omówiliśmy wprowadzenie do Data Science z głównymi składnikami i cechami wprowadzenia do Data Science. Możesz także przejrzeć następujące artykuły:
- Nauka danych a wizualizacja danych
- Pytania do wywiadu Data Science
- Nauka danych a analiza danych
- Analityka predykcyjna a analiza danych
- Algorytmy analizy danych | Rodzaje