
Wprowadzenie do nadzorowanego uczenia się
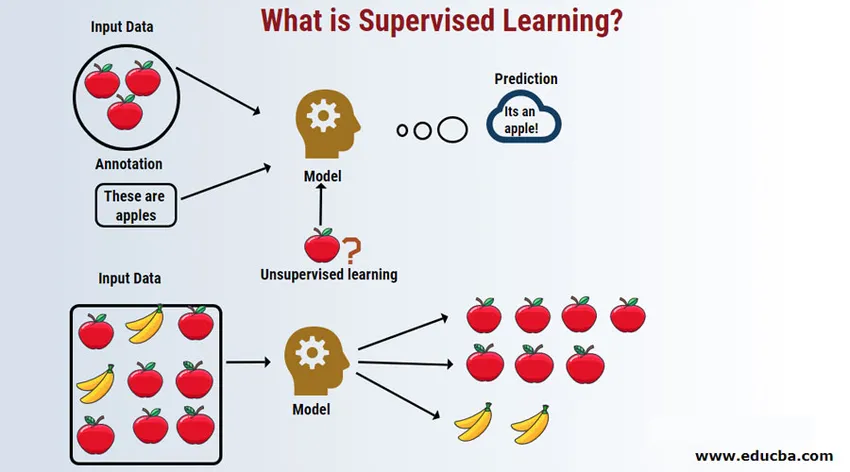
Uczenie nadzorowane to dziedzina uczenia maszynowego, w której pracujemy nad przewidywaniem wartości przy użyciu etykietowanych zestawów danych. Oznakowane zestawy danych wejściowych nazywane są zmienną niezależną, podczas gdy przewidywane wyniki nazywane są zmienną zależną, ponieważ ich wyniki zależą od zmiennej niezależnej. Na przykład wszyscy mamy folder spamu na naszym koncie e-mail (np. Gmail), który automatycznie wykrywa większość wiadomości e-mail zawierających spam / oszustwa z dokładnością większą niż 95%. Działa w oparciu o nadzorowany model uczenia się, w którym mamy zestaw szkoleniowy z etykietowanymi danymi, którymi w tym przypadku są oznaczone wiadomości e-mail ze spamem oznaczone przez użytkowników. Te zestawy szkoleniowe są używane do nauki, które później zostaną wykorzystane do kategoryzacji nowych wiadomości e-mail jako spam, jeśli pasuje do kategorii.
Praca nad nadzorowanym uczeniem maszynowym
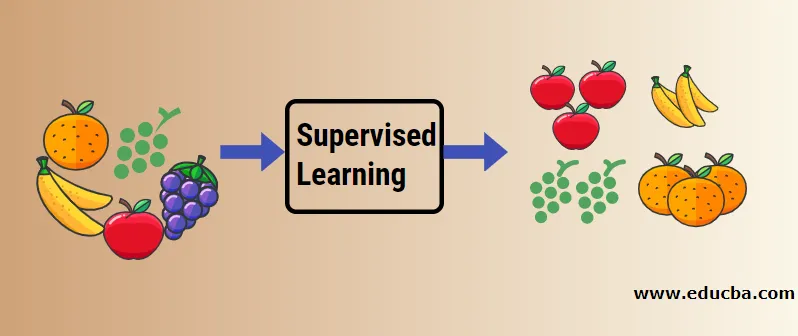
Pozwól nam zrozumieć nadzorowane uczenie maszynowe na podstawie przykładu. Załóżmy, że mamy kosz owoców wypełniony różnymi gatunkami owoców. Naszym zadaniem jest kategoryzowanie owoców na podstawie ich kategorii.
W naszym przypadku rozważaliśmy cztery rodzaje owoców, a są to: jabłko, banan, winogrona i pomarańcze.
Teraz spróbujemy wspomnieć o niektórych wyjątkowych cechach tych owoców, które czynią je wyjątkowymi.
|
Nr S | Rozmiar | Kolor | Kształt |
Imię |
|
1 | Mały | Zielony | Okrągły do owalnego, w kształcie walca Cylindryczny |
Winogrono |
|
2) | Duży | Czerwony | Zaokrąglony kształt z zagłębieniem u góry |
jabłko |
|
3) | Duży | Żółty | Długi zakrzywiony cylinder |
Banan |
| 4 | Duży | Pomarańczowy | Zaokrąglony kształt |
Pomarańczowy |
Powiedzmy teraz, że podniosłeś owoc z kosza z owocami, spojrzałeś na jego cechy, na przykład na przykład jego kształt, rozmiar i kolor, a następnie wywnioskowałeś, że kolor tego owocu jest czerwony, rozmiar, jeśli duży, kształt ma zaokrąglony kształt z zagłębieniem u góry, stąd jest to jabłko.
- Podobnie robisz to samo dla wszystkich pozostałych owoców.
- Najbardziej wysunięta na prawo kolumna („Nazwa owocu”) jest znana jako zmienna odpowiedzi.
- W ten sposób formułujemy nadzorowany model uczenia się, teraz będzie to całkiem łatwe dla każdego nowego (powiedzmy robota lub kosmity) o określonych właściwościach, aby łatwo grupować razem ten sam rodzaj owoców.
Rodzaje nadzorowanego algorytmu uczenia maszynowego
Zobaczmy różne typy algorytmów uczenia maszynowego:
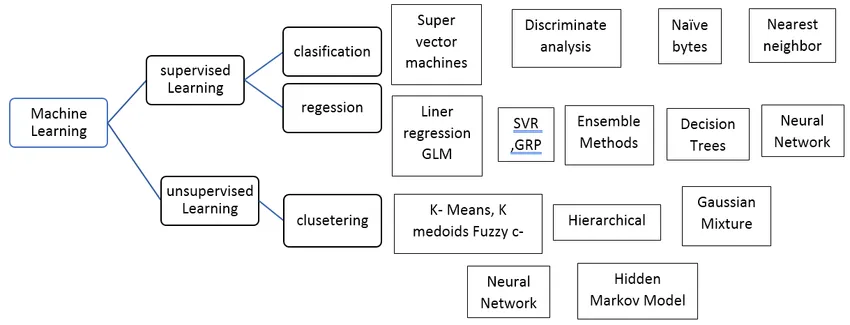
Regresja:
Regresja służy do przewidywania wyniku pojedynczej wartości przy użyciu zestawu danych treningowych. Wartość wyjściowa jest zawsze wywoływana jako zmienna zależna, natomiast dane wejściowe są znane jako zmienna niezależna. Mamy różne rodzaje regresji w nauczaniu nadzorowanym, na przykład
- Regresja liniowa - tutaj mamy tylko jedną zmienną niezależną, która służy do przewidywania wyniku, tj. Zmienną zależną.
- Regresja wielokrotna - tutaj mamy więcej niż jedną zmienną niezależną, która służy do przewidywania wyniku, tj. Zmienną zależną.
- Regresja wielomianowa - tutaj wykres między zmiennymi zależnymi i niezależnymi podąża za funkcją wielomianową. Na przykład najpierw pamięć rośnie z wiekiem, potem osiąga próg w pewnym wieku, a następnie zaczyna się zmniejszać wraz z wiekiem.
Klasyfikacja:
Klasyfikacja nadzorowanych algorytmów uczenia się służy do grupowania podobnych obiektów w unikalne klasy.
- Klasyfikacja binarna - jeśli algorytm próbuje zgrupować 2 odrębne grupy klas, nazywa się to klasyfikacją binarną.
- Klasyfikacja wieloklasowa - jeśli algorytm próbuje grupować obiekty w więcej niż 2 grupy, nazywa się to klasyfikacją wieloklasową.
- Siła - Algorytmy klasyfikacji zwykle działają bardzo dobrze.
- Wady - podatne na nadmierne dopasowanie i mogą być nieograniczone. Na przykład - klasyfikator spamu e - mail
- Regresja / klasyfikacja logistyczna - Gdy zmienna Y jest kategorią binarną (tj. 0 lub 1), do prognozowania używamy regresji logistycznej. Na przykład - przewidywanie, czy dana transakcja kartą kredytową jest oszustwem, czy nie.
- Naiwne klasyfikatory Bayesa - Naiwny klasyfikator Bayesa opiera się na twierdzeniu bayesowskim. Algorytm ten najlepiej nadaje się, gdy wymiary wejściowe są wysokie. Składa się z acyklicznych wykresów, które mają jednego rodzica i wiele węzłów potomnych. Węzły potomne są od siebie niezależne.
- Drzewa decyzyjne - drzewo decyzyjne to struktura przypominająca wykres drzewa, która składa się z węzła wewnętrznego (test na atrybucie), gałęzi oznaczającej wynik testu oraz węzłów liści reprezentujących rozkład klas. Węzeł główny jest najwyższym węzłem. Jest to bardzo szeroko stosowana technika stosowana do klasyfikacji.
- Maszyna wektora wsparcia - maszyna wektora wsparcia lub maszyna SVM wykonuje klasyfikację, znajdując hiperpłaszczyznę, która powinna maksymalizować margines między 2 klasami. Te maszyny SVM są podłączone do funkcji jądra. Dziedziny, w których SVM są szeroko stosowane, to biometria, rozpoznawanie wzorców itp.
Zalety
Poniżej wymieniono niektóre zalety nadzorowanych modeli uczenia maszynowego:
- Wydajność modeli może być zoptymalizowana przez doświadczenia użytkownika.
- Nadzorowane uczenie się przynosi wyniki na podstawie wcześniejszych doświadczeń, a także umożliwia gromadzenie danych.
- Nadzorowane algorytmy uczenia maszynowego mogą być stosowane do implementacji wielu rzeczywistych problemów.
Niedogodności
Wady nauki nadzorowanej są następujące:
- Wysiłek szkolenia nadzorowanych modeli uczenia maszynowego może zająć dużo czasu, jeśli zbiór danych jest większy.
- Klasyfikacja dużych zbiorów danych stanowi czasem większe wyzwanie.
- Być może będziesz musiał poradzić sobie z problemami nadmiernego dopasowania.
- Potrzebujemy wielu dobrych przykładów, jeśli chcemy, aby model działał dobrze podczas szkolenia klasyfikatora.
Dobre praktyki podczas budowania modeli uczenia się
Dobrą praktyką jest tworzenie modeli nadzorowanych maszyn uczących się: -
- Przed zbudowaniem dobrego modelu uczenia maszynowego należy przeprowadzić proces wstępnego przetwarzania danych.
- Trzeba zdecydować, który algorytm najlepiej pasuje do danego problemu.
- Musimy zdecydować, jakiego rodzaju dane zostaną wykorzystane w zestawie szkoleniowym.
- Musi zdecydować o strukturze algorytmu i funkcji.
Wniosek
W naszym artykule dowiedzieliśmy się, czym jest nadzorowane uczenie się i widzieliśmy, że tutaj szkolimy model przy użyciu danych oznaczonych. Następnie przystąpiliśmy do pracy modeli i ich różnych typów. W końcu dostrzegliśmy zalety i wady tych nadzorowanych algorytmów uczenia maszynowego.
Polecane artykuły
Jest to przewodnik po tym, czym jest nadzorowane uczenie się ?. Tutaj omawiamy pojęcia, jak to działa, rodzaje, zalety i wady nauki nadzorowanej. Możesz także przejrzeć nasze inne sugerowane artykuły, aby dowiedzieć się więcej -
- Co to jest głębokie uczenie się
- Uczenie nadzorowane a uczenie głębokie
- Co to jest synchronizacja w Javie?
- Co to jest hosting?
- Sposoby tworzenia drzewa decyzyjnego z zaletami
- Regresja wielomianowa | Zastosowania i funkcje