

Przegląd rodzajów klastrowania
Przed nauczeniem się typów klastrowania zrozumiemy, czym jest klastrowanie i dlaczego jest on tak ważny w branży uczenia maszynowego.
Co to jest klastrowanie? Grupowanie jest procesem, w którym algorytm dzieli punkty danych na określoną liczbę grup w oparciu o zasadę, że podobne punkty danych pozostają blisko siebie i należą do tej samej grupy.
Dlaczego jest to teraz takie ważne? Rozumiemy, że na przykład widzimy sklep z odzieżą online i chcą lepiej zrozumieć swoich klientów, aby mogli skuteczniej realizować swoją strategię reklamową. Nie jest możliwe, aby mieli oni unikalny rodzaj strategii dla każdego klienta, zamiast tego mogą oni podzielić klientów na pewną liczbę grup (na podstawie swoich wcześniejszych zakupów) i mieć oddzielną strategię oddzielnych grup. Dzięki temu firma jest bardziej efektywna, dlatego właśnie klastrowanie jest teraz ważne w branży.
Rodzaje klastrowania
Zasadniczo metody technik grupowania dzielą się na dwa typy: są to metody twarde i metody miękkie. W metodzie klastrowania twardego każdy punkt danych lub obserwacja należy do tylko jednego klastra. W metodzie klastrowania miękkiego każdy punkt danych nie będzie całkowicie należeć do jednego klastra, zamiast tego może być członkiem więcej niż jednego klastra, ma zestaw współczynników członkostwa odpowiadających prawdopodobieństwu bycia w danym klastrze.
Obecnie stosowane są różne typy metod grupowania, tutaj w tym artykule zobaczymy niektóre z najważniejszych, takie jak klastrowanie hierarchiczne, klastrowanie partycjonujące, klastrowanie rozmyte, klastrowanie oparte na gęstości i klastrowanie oparte na modelu dystrybucji. Omówmy teraz każdy z nich na przykładzie:
1. Podział na klastry
Partycjonowanie Klastrowanie jest rodzajem techniki klastrowania, która dzieli zestaw danych na określoną liczbę grup. (Na przykład wartość K w KNN i decyzja zostanie podjęta przed szkoleniem modelu). Można go również nazwać metodą opartą na centroidach. W tym podejściu centrum skupień (centroid) jest tworzone w taki sposób, że odległość punktów danych w tym skupisku jest minimalna, gdy jest obliczana z innymi centrami skupień. Najpopularniejszym przykładem tego algorytmu jest algorytm KNN. Tak wygląda algorytm klastrowania partycjonowania
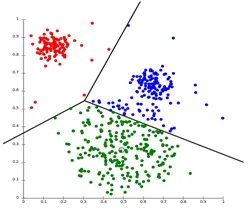
2. Hierarchiczne grupowanie
Hierarchiczne grupowanie jest rodzajem techniki klastrowania, która dzieli ten zestaw danych na kilka klastrów, w których użytkownik nie określa liczby klastrów, które mają zostać wygenerowane przed szkoleniem modelu. Ten rodzaj techniki klastrowania jest również znany jako metody oparte na łączności. W tej metodzie proste dzielenie zestawu danych nie zostanie wykonane, podczas gdy zapewnia nam hierarchię klastrów, które łączą się ze sobą po pewnym dystansie. Po wykonaniu hierarchicznego grupowania w zbiorze danych wynikiem będzie drzewna reprezentacja punktów danych (Dendogram), które są podzielone na klastry. Tak wygląda hierarchiczne grupowanie po zakończeniu treningu
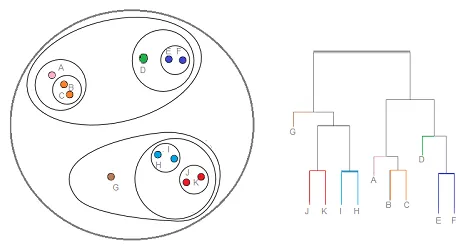
Link do źródła: Hierarchical Clustering
W przypadku klastrowania partycjonującego i klastrowego hierarchicznego jedną główną różnicę, którą możemy zauważyć, jest klastrowanie partycjonowane, z góry ustalimy wartość liczby klastrów, w których chcemy podzielić zestaw danych, i nie określamy wstępnie tej wartości w hierarchicznym klastrowaniu .
3. Grupowanie oparte na gęstości
W tym grupowaniu klastry techniki będą tworzone przez segregację różnych regionów gęstości w oparciu o różne gęstości na wykresie danych. Grupowanie przestrzenne oparte na gęstości i aplikacja z hałasem (DBSCAN) jest najczęściej stosowanym algorytmem w tego rodzaju technice. Główną ideą tego algorytmu jest minimalna liczba punktów, które zawierają się w pobliżu danego promienia dla każdego punktu w klastrze. Jak dotąd w omawianych powyżej technikach skupiania, jeśli dokładnie się przyjrzysz, zauważymy jedną wspólną rzecz we wszystkich technikach, które mają kształt utworzonych skupisk, mają kształt kulisty, owalny lub wklęsły. DBSCAN może tworzyć klastry w różnych kształtach, ten typ algorytmu jest najbardziej odpowiedni, gdy zestaw danych zawiera szum lub wartości odstające. Tak wygląda algorytm klastrowania przestrzennego oparty na gęstości po zakończeniu treningu.
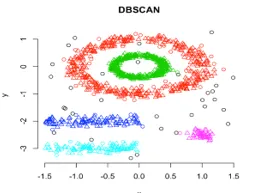
Link do źródła: Grupowanie oparte na gęstości
4. Grupowanie oparte na modelu dystrybucji
W tego rodzaju grupowaniu klastry techniki są tworzone przez identyfikację przez prawdopodobieństwo, że wszystkie punkty danych w klastrze pochodzą z tego samego rozkładu (normalny, gaussowski). Najpopularniejszym algorytmem w tego typu technice jest grupowanie metodą Expectation-Maximization (EM) przy użyciu modeli mieszanki Gaussa (GMM).
Normalne techniki klastrowania, takie jak klastrowanie hierarchiczne i klastrowanie partycjonujące, nie są oparte na modelach formalnych, KNN w klastrowaniu partycjonującym daje różne wyniki z różnymi wartościami K. Ponieważ KNN i KMN uważają średnią dla centrum skupień, w niektórych przypadkach nie jest najlepiej odpowiedni w przypadku modeli mieszanki Gaussa, zakładamy, że punkty danych są rozkładem Gaussa, w ten sposób mamy dwa parametry opisujące kształt średniej skupienia i odchylenie standardowe. W ten sposób dla każdego skupienia przypisywany jest jeden rozkład Gaussa, aby uzyskać optymalne wartości tych parametrów (średnią i odchylenie standardowe), stosuje się algorytm optymalizacji zwany Maksymalizacją oczekiwań. Tak wygląda EM - GMM po treningu.
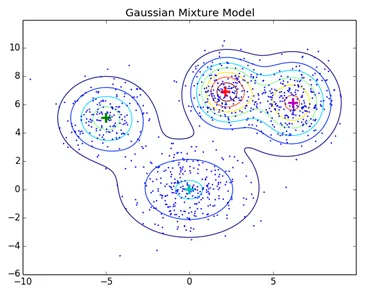
Link do źródła: Grupowanie oparte na modelu dystrybucji
5. Grupowanie rozmyte
Należy do gałęzi technik klastrowania metodą miękką, podczas gdy wszystkie wyżej wymienione techniki klastrowania należą do technik klastrowania metodą trudną. W tego rodzaju technice klastrowania punkty znajdujące się blisko środka mogą być częścią drugiego skupienia w stopniu wyższym niż punkty na krawędzi tego samego skupienia. Prawdopodobieństwo, że punkt należy do danego klastra, jest wartością z zakresu od 0 do 1. Najpopularniejszym algorytmem w tego rodzaju technice jest FCM (algorytm rozmycia C-średnich). Tutaj centroid klastra jest obliczany jako średnia wszystkich punktów, ważonych prawdopodobieństwem przynależności do klastra.
Wniosek - rodzaje grupowania
Oto niektóre z różnych technik klastrowania, które są obecnie w użyciu. W tym artykule omówiliśmy jeden popularny algorytm w każdej technice klastrowania. Musimy wybrać rodzaj używanej technologii, w oparciu o nasz zestaw danych i wymagania, które musimy spełnić.
Polecane artykuły
Jest to przewodnik po typach klastrowania. Tutaj omawiamy różne rodzaje grupowania z ich przykładami. Możesz także zapoznać się z następującymi artykułami, aby dowiedzieć się więcej -
- Hierarchiczny algorytm grupowania
- Grupowanie w uczenie maszynowe
- Rodzaje algorytmów uczenia maszynowego
- Rodzaje technik analizy danych
- Jak używać i usuwać hierarchię w Tableau?
- Kompletny przewodnik po typach analizy danych