
Co to jest algorytm SVM?
SVM oznacza Support Vector Machine. SVM jest nadzorowanym algorytmem uczenia maszynowego, który jest powszechnie stosowany do wyzwań związanych z klasyfikacją i regresją. Typowe zastosowania algorytmu SVM to system wykrywania włamań, rozpoznawanie pisma ręcznego, przewidywanie struktury białek, wykrywanie steganografii na obrazach cyfrowych itp.
W algorytmie SVM każdy punkt jest reprezentowany jako element danych w przestrzeni n-wymiarowej, gdzie wartość każdej cechy jest wartością określonej współrzędnej.
Po wykreśleniu dokonano klasyfikacji poprzez znalezienie płaszczyzny szumu, która odróżnia dwie klasy. Zobacz poniższy obraz, aby zrozumieć tę koncepcję.
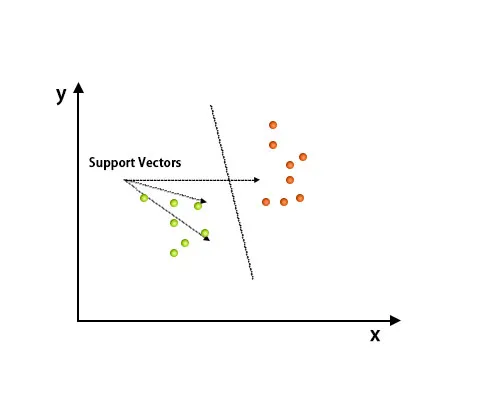
Algorytm obsługi maszyny wektorowej służy głównie do rozwiązywania problemów z klasyfikacją. Wektory pomocnicze to nic innego jak współrzędne każdego elementu danych. Support Vector Machine to granica, która wyróżnia dwie klasy za pomocą hiperpłaszczyzny.
Jak działa algorytm SVM?
W powyższej sekcji omówiliśmy różnicowanie dwóch klas za pomocą hiperpłaszczyzny. Teraz zobaczymy, jak działa ten algorytm SVM.
Scenariusz 1: Zidentyfikuj właściwą hiperpłaszczyznę
Tutaj wzięliśmy trzy hiperpłaszczyzny, tj. A, B i C. Teraz musimy zidentyfikować właściwą hiperpłaszczyznę, aby sklasyfikować gwiazdę i okrąg.
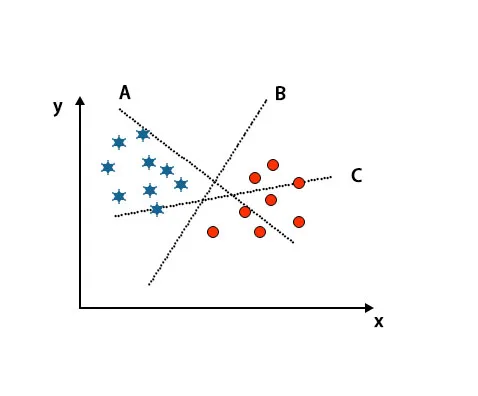
Aby zidentyfikować właściwą hiperpłaszczyznę, powinniśmy znać zasadę kciuka. Wybierz hiperpłaszczyznę, która odróżnia dwie klasy. Na powyższym obrazie hiperpłaszczyzna B bardzo dobrze różnicuje dwie klasy.
Scenariusz 2: Zidentyfikuj właściwą hiperpłaszczyznę
Tutaj wzięliśmy trzy hiperpłaszczyzny, tj. A, B i C. Te trzy hiperpłaszczyzny już bardzo dobrze różnicują klasy.
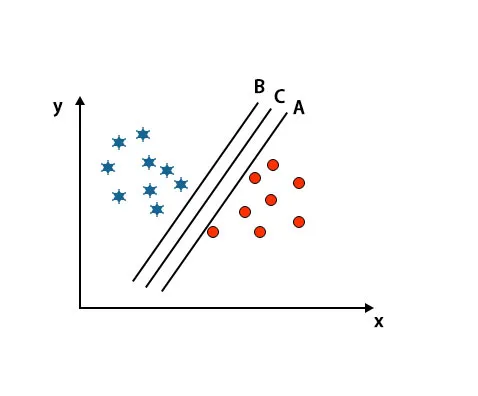
W tym scenariuszu, aby zidentyfikować właściwą hiperpłaszczyznę, zwiększamy odległość między najbliższymi punktami danych. Odległość ta jest niczym innym jak marginesem. Zobacz zdjęcie poniżej.
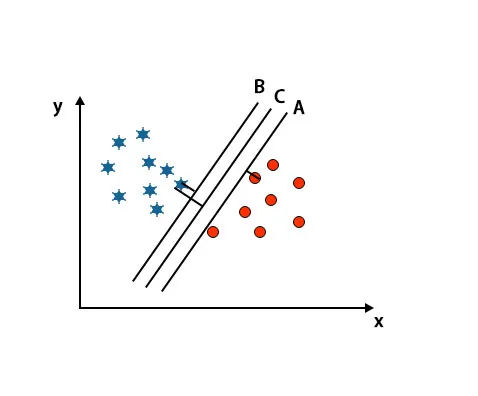
Na wyżej wspomnianym obrazie margines hiperpłaszczyzny C jest wyższy niż hiperpłaszczyzna A i hiperpłaszczyzna B. Zatem w tym scenariuszu C jest prawą hiperpłaszczyzną. Jeśli wybierzemy hiperpłaszczyznę z minimalnym marginesem, może to prowadzić do błędnej klasyfikacji. Dlatego wybraliśmy hiperpłaszczyznę C z maksymalnym marginesem ze względu na wytrzymałość.
Scenariusz 3: Zidentyfikuj właściwą hiperpłaszczyznę
Uwaga: Aby zidentyfikować hiperpłaszczyznę, postępuj zgodnie z tymi samymi regułami, jak wspomniano w poprzednich sekcjach.
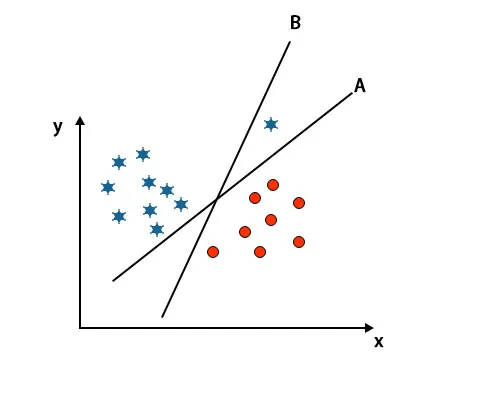
Jak widać na powyższym obrazku margines hiperpłaszczyzny B jest większy niż margines hiperpłaszczyzny A, dlatego niektórzy wybiorą hiperpłaszczyznę B jako prawą. Ale w algorytmie SVM wybiera ten hiperpłaszczyznę, która klasyfikuje klasy dokładnie przed maksymalizacją marginesu. W tym scenariuszu hiperpłaszczyzna A sklasyfikowała wszystko dokładnie i występuje pewien błąd w klasyfikacji hiperpłaszczyzny B. Dlatego A jest właściwą hiperpłaszczyzną.
Scenariusz 4: Klasyfikuj dwie klasy
Jak widać na poniższym obrazie, nie jesteśmy w stanie rozróżnić dwóch klas za pomocą linii prostej, ponieważ jedna gwiazda znajduje się jako odstająca w drugiej klasie koła.
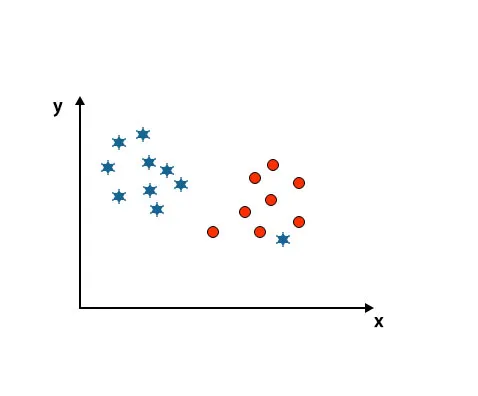
Tutaj jedna gwiazda należy do innej klasy. Dla klasy gwiazd ta gwiazda jest wartością odstającą. Ze względu na właściwość niezawodności algorytmu SVM znajdzie właściwą hiperpłaszczyznę z wyższym marginesem ignorującym wartość odstającą.
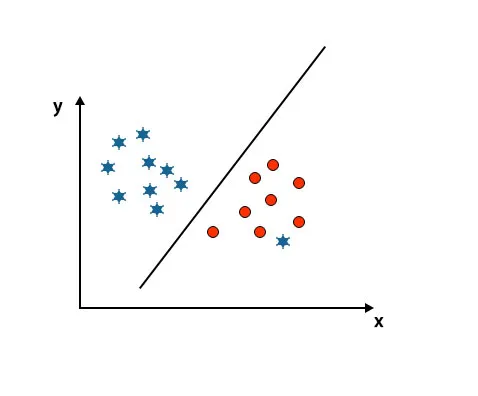
Scenariusz 5: Drobna hiperpłaszczyzna dla rozróżnienia klas
Do tej pory wyglądaliśmy na liniową hiperpłaszczyznę. Na poniższym obrazie nie mamy liniowej hiperpłaszczyzny między klasami.
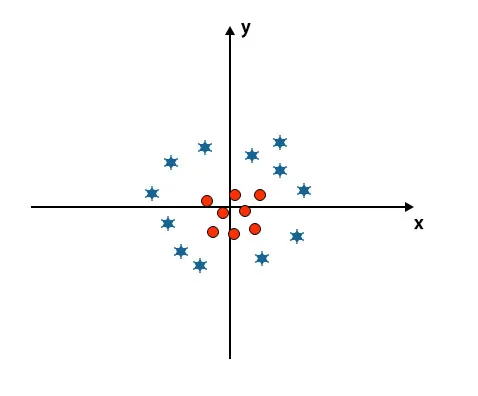
Aby sklasyfikować te klasy, SVM wprowadza dodatkowe funkcje. W tym scenariuszu użyjemy tej nowej funkcji z = x 2 + y 2.
Drukuje wszystkie punkty danych na osi X i Z.

Uwaga
- Wszystkie wartości na osi z powinny być dodatnie, ponieważ z jest równe sumie x do kwadratu i y do kwadratu.
- Na wyżej wspomnianym wykresie czerwone kółka są zamknięte do początku osi X i osi Y, co prowadzi do obniżenia wartości Z, a gwiazda jest dokładnie przeciwna do okręgu, jest oddalona od początku osi X i oś y, prowadząc wartość z do wysokiej.
W algorytmie SVM łatwo jest sklasyfikować za pomocą hiperpłaszczyzny liniowej między dwiema klasami. Ale pojawia się pytanie, czy powinniśmy dodać tę funkcję SVM w celu identyfikacji hiperpłaszczyzny. Odpowiedź brzmi: nie, aby rozwiązać ten problem, SVM ma technikę, która jest powszechnie znana jako sztuczka jądra.
Sztuczka jądra to funkcja przekształcająca dane w odpowiednią formę. W algorytmie SVM stosowane są różne typy funkcji jądra, tj. Wielomianowa, liniowa, nieliniowa, radialna funkcja podstawowa itp. W tym przypadku przy użyciu sztuczki jądra niską wymiarową przestrzeń wejściową przekształca się w przestrzeń wyższego wymiaru.
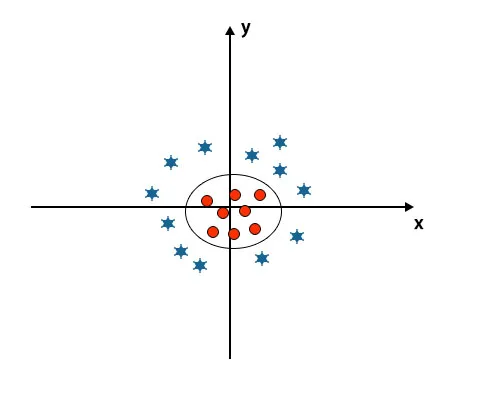
Kiedy spojrzymy na hiperpłaszczyznę, początek osi i osi y, wygląda jak koło. Zobacz zdjęcie poniżej.
Zalety algorytmu SVM
- Nawet jeśli dane wejściowe są nieliniowe i nierozdzielne, maszyny SVM generują dokładne wyniki klasyfikacji ze względu na swoją solidność.
- W funkcji decyzyjnej wykorzystuje podzbiór punktów treningowych zwanych wektorami wspierającymi, a zatem jest wydajny pod względem pamięci.
- Przydatne jest rozwiązanie dowolnego złożonego problemu za pomocą odpowiedniej funkcji jądra.
- W praktyce modele SVM są uogólnione, z mniejszym ryzykiem nadmiernego dopasowania w SVM.
- SVM doskonale nadaje się do klasyfikacji tekstu i znalezienia najlepszego separatora liniowego.
Wady algorytmu SVM
- Praca z dużymi zestawami danych zajmuje dużo czasu.
- Trudno zrozumieć ostateczny model i indywidualny wpływ.
Wniosek
Został on poprowadzony do obsługi algorytmu Vector Machine, który jest algorytmem uczenia maszynowego. W tym artykule omówiliśmy algorytm SVM, sposób jego działania i jego zalety w szczegółach.
Polecane artykuły
Jest to przewodnik po algorytmie SVM. Tutaj omawiamy jego działanie ze scenariuszem, zaletami i wadami algorytmu SVM. Możesz także przejrzeć następujące artykuły, aby dowiedzieć się więcej -
- Algorytmy eksploracji danych
- Techniki eksploracji danych
- Co to jest uczenie maszynowe?
- Narzędzia do uczenia maszynowego
- Przykłady algorytmu C ++