

Jak zainstalować Apache
Zanim przejdziemy do instalacji części Apache, najpierw będziemy mieli ogólny przegląd Apache i tego, jak jest on wykorzystywany w analizie danych.
Co to jest Apache?

Apache Web Server to serwer HTTP, który prezentuje witryny odwiedzającym odwiedzającym Twój serwer. Więc jeśli chcesz wdrożyć witrynę internetową dla firmy lub organizacji, najprawdopodobniej użyjesz do tego Apache.
Istnieją inne serwery HTTP, takie jak IIS, ale Apache jest standardem, z którego korzysta większość osób, bez względu na to, czy korzystają one z systemu Linux, Windows czy Mac. Apache to domyślna opcja, do której dociera większość ludzi, ponieważ jest dobrze znana, bardzo niezawodna i darmowa.
Jednak jedną rzeczą do zrealizowania w Apache jest to, że jest to serwer HTTP, więc jeśli zainstalujesz to na Linuxie, Windowsie lub Macu, jedyne, co możesz zrobić, to prezentować statyczne witryny odwiedzającym odwiedzającym Twój serwer. Dlatego jeśli kodujesz witrynę HTML bez dodatkowych języków programowania innych niż JavaScript, możesz użyć tego tylko na serwerze Apache. Możesz podłączyć wszystkie tagi do serwera Apache i zaprezentować je odwiedzającym.
Jak wykorzystał Apache w Data Science?
Data Science to najbardziej poszukiwany kierunek studiów we współczesnym świecie. Data Scientist jest uważany za najseksowniejszą pracę w XXI wieku, a profesjonaliści z różnych dyscyplin chcą się uczyć i zostać Data Scientist. Apache odgrywa kluczową rolę dla każdego entuzjasty nauki danych, ponieważ potrzebują wystarczającej wiedzy na temat ekosystemu Apache Hadoop.
Ekosystem Apache Hadoop
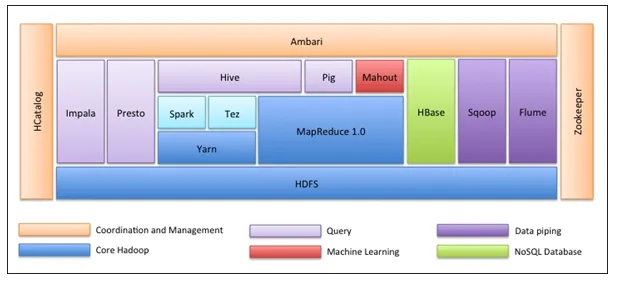
Pierwszą rzeczą jest to, że ekosystem Hadoop nie jest jednym narzędziem. To nie jest język programowania ani pojedynczy framework. Jest to grupa narzędzi używanych wspólnie przez różne firmy w różnych domenach do wielu zadań. Poniżej omówimy kolejno każde narzędzie: -
- Apache HDFS (Hadoop Distributed File System) to jednostka pamięci Hadoop, która może przechowywać ustrukturyzowane, częściowo ustrukturyzowane i nieustrukturyzowane dane. HDFS ma metadane, które utrzymują plik dziennika o przechowywanych danych. Ma dwa komponenty - NameNode i DataNode.
- Apache Yarn jest negocjatorem zasobów, który wykonuje wszystkie czynności związane z przetwarzaniem, takie jak planowanie zadań, przydzielanie zasobów itp. Ma dwie usługi - po pierwsze jest menedżerem zasobów, który planuje aplikacje działające na Yarn. Drugi to menedżer węzłów, który monitoruje wykorzystanie zasobów .
- Apache Map Reduce to komponent przetwarzania danych w Hadoop, który przetwarza duże zestawy danych przy użyciu przetwarzania rozproszonego i równoległego w oparciu o funkcje Map, Sortuj i Losuj oraz Zmniejsz. Funkcja mapy filtruje dane, następnie sortuje i tasuje, a na końcu Zmniejsza agreguje funkcje i podsumowuje wynik.
- Świnia Apache używana głównie w ETL. Składa się z dwóch części - Pig Latin i środowiska uruchomieniowego Pig. Pig Latin to język używany do przetwarzania danych za pomocą zapytania, natomiast środowisko wykonawcze Pig to środowisko wykonawcze. Jedna linia Pig Latin jest prawie równa 100 liniom kodu Reduce Map. Proces obejmuje najpierw załadowanie danych, a następnie grupowanie, sortowanie, filtrowanie i przechowywanie w HDFS.
- Apache Hive korzysta z zapytania podobnego do SQL do analizy danych w środowisku rozproszonym. Składa się z dwóch komponentów - wiersza polecenia Hive i serwera JDBC / ODBC, a używany język to HiveQL.
- Apache Mahout to biblioteka uczenia maszynowego napisana w Javie i używana do tworzenia aplikacji uczenia maszynowego, takich jak klastrowanie, klasyfikacja lub regresja. Ma wbudowane różne algorytmy dla różnych przypadków użycia.
- Apache HBase to baza danych NoSQL napisana w Javie, która działa na platformie Hadoop. Jest zbudowany w oparciu o BigTable Google i jest w stanie obsłużyć wszystkie rodzaje danych.
- Apache Sqoop to narzędzie do przetwarzania danych, które służy do masowego przesyłania danych strukturalnych między RDBMS i Hadoop.
- Apache Flume to kolejne narzędzie do przetwarzania danych, które jest używane do częściowo ustrukturyzowanego i nieustrukturyzowanego transferu danych między Hadoop i innymi źródłami danych.
- ZooKeeper jest koordynatorem, który zapewnia koordynację różnych narzędzi w ekosystemie Hadoop.
- Apache Ambari jest menedżerem klastrów, który zarządza klastrami Hadoop, zarządza nimi, a także monitoruje ich zdrowie i status.
- Apache Tez to nowe narzędzie w ekosystemie Hadoop, które przyspiesza przetwarzanie zapytań w Hadoop.
- Apache Presto to silnik zapytań rozproszonych SQL typu open source, który umożliwia obsługę zapytań na wielu platformach.
- Apache HCatalog to system zarządzania metadanymi i tabelami dla Hadoop, który umożliwia interoperacyjność między narzędziami do przetwarzania danych. Pomaga także użytkownikom wybrać najlepsze narzędzia dla ich środowisk.
- Apache Spark jest najczęściej używaną i popularną platformą wśród Data Scientist. Jest to szybki system klastrowy, który optymalizuje wykorzystanie zasobów w przypadku wielu iteracyjnych zadań. Zapewnia elastyczność zarówno przetwarzania wsadowego, jak i analizy danych w czasie rzeczywistym.
Poniżej znajdują się kroki, aby zainstalować Apache
Jak dotąd dowiedzieliśmy się o Apache i o tym, jak jest on przydatny dla każdego, kto chce się uczyć Data Science lub Big Data Analytics. Teraz zanurkujemy i zainstalujemy apache w systemie Windows w oparciu o poniższe kroki.
- Przejdź do https://httpd.apache.org/ i kliknij link Pobierz w sekcji Apache httpd 2.4.38 Released.

- Nastąpi przejście do następnej strony, a następnie kliknij polecenie Pliki dla systemu Microsoft Windows.
- Kliknij na Apache Lounge.

- Możesz pobrać 32-bitowy lub 64-bitowy plik zip w zależności od systemu operacyjnego Windows. Tutaj pobierzemy wersję 64-bitową. Kliknij odpowiedni link .zip, aby pobrać.

- Teraz wymaga C ++ Redistributable Visual Studio 2017. Więc pobierzemy go z odpowiedniego linku 32-bitowego lub 64-bitowego

- Po pobraniu obu plików przejdziemy do pobranej lokalizacji i najpierw zainstalujemy C ++ Redistributable Visual Studio 2017. Kliknij dwukrotnie plik .exe.

- Zaznacz „Zgadzam się” i kliknij Zainstaluj.

- Trwa instalacja Apache.
- Po zakończeniu otrzymasz wiadomość taką jak ta. Kliknij Zamknij, aby zakończyć instalację.
- Teraz przejdź do folderu, w którym pobierasz plik zip Apache. Kliknij go prawym przyciskiem myszy i wybierz tutaj wyciąg.
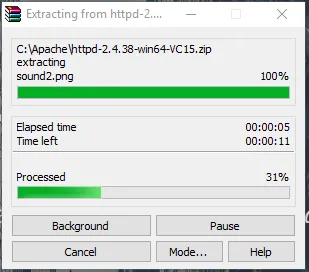
- Teraz utworzymy folder Apache24. Skopiuj ten folder na dysk C, a następnie dodamy ścieżkę do zmiennych środowiskowych systemu.
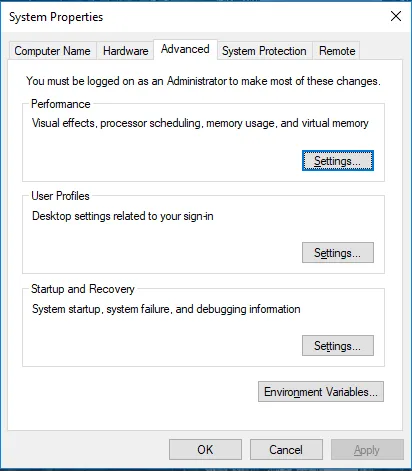
Przejdź do Właściwości systemu -> zakładka Zaawansowane -> Kliknij przycisk Zmienne środowiskowe poniżej.
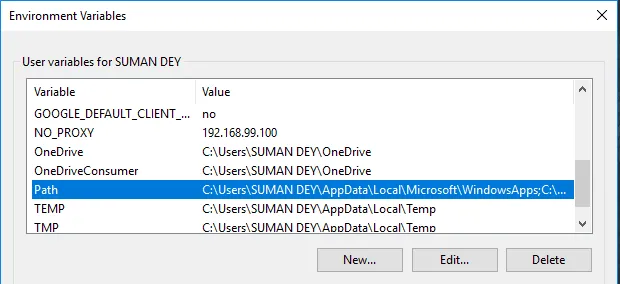
- W Zmienne znajdź Ścieżkę i kliknij Edytuj.
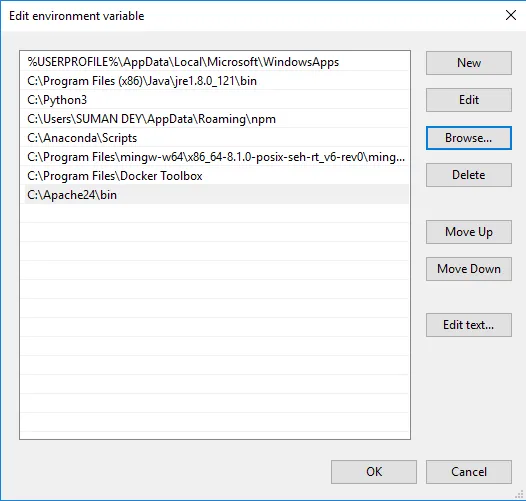
- Kliknij Przeglądaj -> Idź do dysku C folder Apache24 -> Wybierz folder bin -> Kliknij OK.
- Zainstalujemy Apache jako usługę Windows. Uruchom wiersz polecenia jako administrator. Wpisz httpd –k install i naciśnij klawisz Enter.
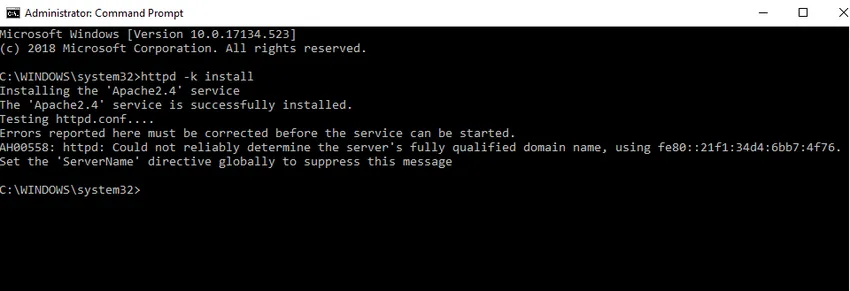
- Sprawdzimy instalację usługi Apache. Kliknij ikonę Windows i wpisz usługi. Kliknij aplikację Usługi i znajdź usługę o nazwie Apache24.

- Aby uruchomić serwer Apache, kliknij go prawym przyciskiem myszy i kliknij przycisk Start. Status zmieni się na „Uruchomiony”.
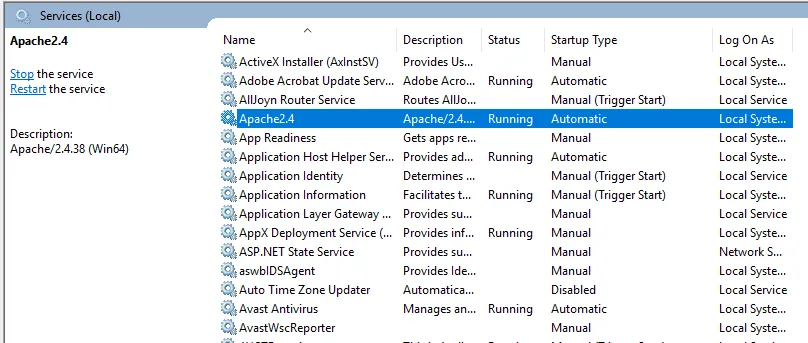
- Możemy przetestować za pomocą przeglądarki. Otwórz przeglądarkę i przejdź do http: // localhost i naciśnij Enter. Komunikat „To działa!” pojawi się, aby potwierdzić pomyślną instalację Apache.
Polecane artykuły
Jest to przewodnik na temat instalacji Apache. Tutaj omówiliśmy Instrukcje i różne kroki, aby zainstalować Apache. Możesz także spojrzeć na następujący artykuł, aby dowiedzieć się więcej -
- Pytania do wywiadu Apache
- Apache Spark vs Apache Flink
- Apache Hadoop vs Apache Spark
- Apache Kafka vs Flume
- Kafka vs Kinesis | Najważniejsze różnice