

Wprowadzenie do metod eksploracji danych
Dane rosną codziennie na ogromną skalę. Ale wszystkie zebrane lub zebrane dane nie są przydatne. Znaczące dane należy oddzielić od danych zaszumionych (dane bez znaczenia). Ten proces separacji odbywa się za pomocą eksploracji danych.
Co to jest Data Mining?
Eksploracja danych to proces uzyskiwania przydatnych informacji lub wiedzy z ogromnej ilości danych (lub dużych zbiorów danych). Luka między danymi a informacjami została zmniejszona dzięki zastosowaniu różnych narzędzi do eksploracji danych. Eksploracja danych może być również określana jako Odkrycie wiedzy z danych lub KDD .
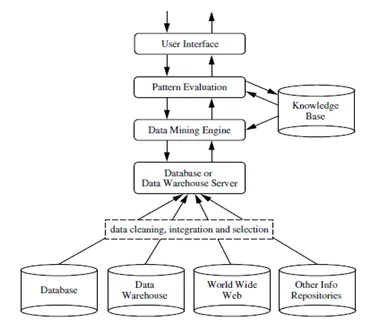
Źródła: - www.ques10.com
Eksploracja danych może odbywać się na różnych typach baz danych i repozytoriach informacji, takich jak relacyjne bazy danych, hurtownie danych, transakcyjne bazy danych, strumienie danych i wiele innych.
Różne metody eksploracji danych:
Istnieje wiele metod wykorzystywanych do eksploracji danych, ale kluczowym krokiem jest wybranie spośród nich odpowiedniej metody zgodnie z opisem firmy lub problemu. Te metody eksploracji danych pomagają przewidywać przyszłość, a następnie podejmować odpowiednie decyzje. Pomagają również w analizie trendów rynkowych i zwiększaniu przychodów firmy.
Niektóre metody eksploracji danych to:
- Stowarzyszenie
- Klasyfikacja
- Analiza skupień
- Prognoza
- Wzory sekwencyjne lub śledzenie wzorców
- Drzewa decyzyjne
- Analiza wartości odstających lub analiza anomalii
- Sieć neuronowa
Pozwól nam zrozumieć po kolei wszystkie metody eksploracji danych.
1. Stowarzyszenie:
Jest to metoda stosowana do znalezienia korelacji między dwoma lub więcej elementami poprzez identyfikację ukrytego wzorca w zbiorze danych, a zatem nazywana również analizą relacji . Metodę tę stosuje się w analizie koszyka rynkowego, aby przewidzieć zachowanie klienta.
Załóżmy, że kierownik marketingu supermarketu chce ustalić, które produkty są często kupowane razem.
Jako przykład,
Kupuje (x, „piwo”) -> kupuje (x, „frytki”) (wsparcie = 1%, pewność = 50%)
- Tutaj x reprezentuje klienta kupującego piwo i frytki razem.
- Zaufanie pokazuje pewność, że jeśli klient kupi piwo, istnieje 50% szans, że on / ona również kupi żetony.
- Wsparcie oznacza, że 1% wszystkich analizowanych transakcji wykazało, że piwo i frytki zostały zakupione razem.
Można rozważyć wiele podobnych przykładów, takich jak chleb z masłem lub komputer i oprogramowanie.
Istnieją dwa rodzaje reguł asocjacyjnych:
- Reguła asocjacji jednowymiarowej: Reguły te zawierają powtarzany pojedynczy atrybut.
- Wielowymiarowa reguła asocjacji: Reguły te zawierają wiele powtarzających się atrybutów.
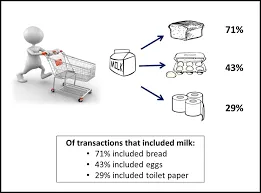
https://bit.ly/2N61gzR
2. Klasyfikacja:
Ta metoda eksploracji danych służy do rozróżnienia elementów w zestawach danych na klasy lub grupy. Pomaga dokładnie przewidzieć zachowanie elementów w grupie. Jest to proces dwuetapowy:
- Etap uczenia się (faza szkolenia): W tym przypadku algorytm klasyfikacji buduje klasyfikator poprzez analizę zestawu treningowego.
- Etap klasyfikacji: Dane testowe służą do oszacowania dokładności lub precyzji reguł klasyfikacji.
Na przykład firma bankowa używa do identyfikacji wnioskodawców o niskim, średnim lub wysokim ryzyku kredytowym. Podobnie badacz medyczny analizuje dane dotyczące raka, aby przewidzieć, który lek przepisać pacjentowi.
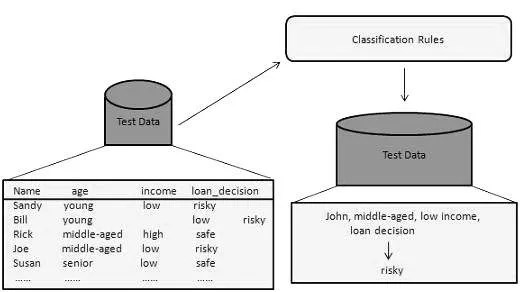
Źródła: - www.tutorialspoint.com
3. Analiza skupień:
Klastrowanie jest prawie podobne do klasyfikacji, ale w tym klastrze są tworzone w zależności od podobieństwa elementów danych. Różne klastry mają różne lub niepowiązane ze sobą obiekty. Jest również nazywany segmentacją danych, ponieważ dzieli duże zestawy danych na klastry zgodnie z podobieństwami.
Stosowane są różne metody grupowania:
- Hierarchiczne metody aglomeracyjne
- Metody oparte na siatce
- Metody partycjonowania
- Metody oparte na modelach
- Metody oparte na gęstości
Podobny przykład osób ubiegających się o pożyczkę można również rozważyć tutaj. Istnieje kilka różnic, które przedstawiono na poniższym rysunku.
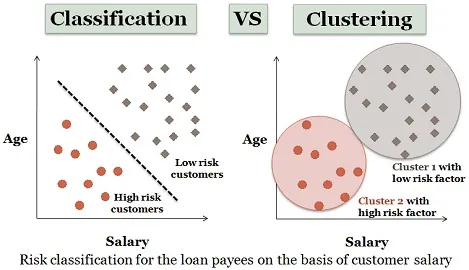
https://bit.ly/2N6aZpP
4. Prognozy:
Ta metoda służy do przewidywania przyszłości na podstawie przeszłych i obecnych trendów lub zestawu danych. Prognozowanie stosuje się głównie w połączeniu z innymi metodami eksploracji danych, takimi jak klasyfikacja, dopasowanie wzorców, analiza trendów i relacje.
Na przykład, jeśli kierownik sprzedaży w supermarkecie chciałby przewidzieć kwotę przychodów, które wygenerowałby każdy produkt na podstawie wcześniejszych danych o sprzedaży. Modeluje funkcję ciągłej wyceny, która przewiduje brak wartości danych liczbowych.

Źródła: - data-mining.philippe-fournier
Analiza regresji jest najlepszym wyborem do wykonania prognozy. Można go użyć do ustalenia zależności między zmiennymi niezależnymi a zmiennymi zależnymi.
5. Wzorce sekwencyjne lub śledzenie wzorców:
Ta metoda eksploracji danych służy do identyfikowania wzorców, które często występują przez pewien okres czasu.
Na przykład kierownik sprzedaży firmy odzieżowej widzi, że sprzedaż kurtek wydaje się rosnąć tuż przed sezonem zimowym lub sprzedaż w piekarni wzrasta w okresie Bożego Narodzenia lub Sylwestra.
Spójrzmy na przykład z wykresem
Źródła: - data-mining.philippe-fournier-viger
6. Drzewa decyzyjne:
Drzewo decyzyjne to struktura drzewa (jak sama nazwa wskazuje), gdzie
- Każdy węzeł wewnętrzny reprezentuje test atrybutu.
- Gałąź oznacza wynik testu.
- Węzły końcowe posiadają etykietę klasy.
- Najwyższy węzeł jest węzłem głównym, który ma proste pytanie, które ma dwie lub więcej odpowiedzi. W związku z tym drzewo rośnie i generowana jest struktura blokowa.
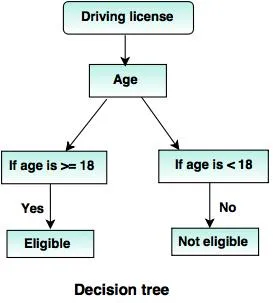
Źródła: - www.tutorialride.com
W tej decyzji rząd drzewa klasyfikuje obywateli poniżej 18 roku życia lub powyżej 18 lat. Pomogłoby im to zdecydować, czy należy wydać licencję konkretnemu obywatelowi, czy nie.
7. Analiza zewnętrzna lub analiza anomalii:
Ta metoda eksploracji danych służy do identyfikowania elementów danych, które nie są zgodne z oczekiwanym wzorcem lub oczekiwanym zachowaniem. Te nieoczekiwane elementy danych są uważane za wartości odstające lub szum. Są one pomocne w wielu dziedzinach, takich jak wykrywanie oszustw związanych z kartami kredytowymi, wykrywanie włamań, wykrywanie usterek itp. Nazywa się to również wydobywaniem odstającym .
Załóżmy na przykład, że poniższy wykres jest wykreślony przy użyciu niektórych zestawów danych w naszej bazie danych.
Tak więc narysowana jest linia najlepszego dopasowania. Punkty leżące w pobliżu linii pokazują oczekiwane zachowanie, podczas gdy punkt daleko od linii jest wartością odstającą.
Pomogłoby to wykryć anomalie i odpowiednio podjąć możliwe działania.
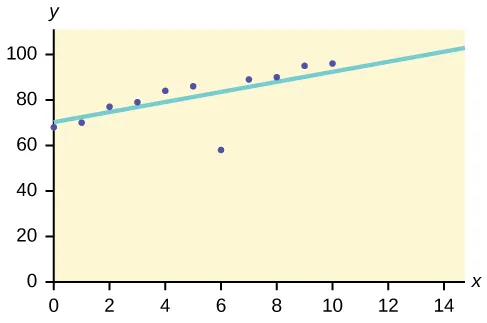
https://bit.ly/2GrgjDP
8. Sieć neuronowa:
Ta metoda lub model eksploracji danych opiera się na biologicznych sieciach neuronowych. Jest to zbiór neuronów, takich jak jednostki przetwarzające z ważonymi połączeniami między nimi. Służą do modelowania relacji między wejściami i wyjściami. Służy do klasyfikacji, analizy regresji, przetwarzania danych itp. Ta technika działa na trzech filarach
- Model
- Algorytm uczenia się (nadzorowany lub nienadzorowany)
- Funkcja aktywacji
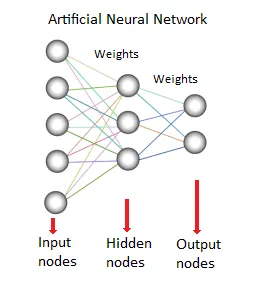
Źródła: - www.saedsayad.com
Polecane artykuły
To był przewodnik po metodach eksploracji danych W tym przykładzie omówiliśmy na czym polega eksploracja danych i różne typy metod eksploracji danych. Możesz także przejrzeć następujące artykuły, aby dowiedzieć się więcej -
- Oprogramowanie do analizy Big Data
- Pytania do wywiadu dotyczącego struktury danych
- Ważne techniki eksploracji danych
- Architektura Data Mining