

Różnica między Hadoop a Hive
Hadoop:
Hadoop to platforma lub oprogramowanie, które zostało wymyślone do zarządzania dużymi danymi lub dużymi danymi. Hadoop służy do przechowywania i przetwarzania dużych danych rozproszonych w klastrze serwerów towarowych.
Hadoop przechowuje dane za pomocą rozproszonego systemu plików Hadoop i przetwarza je / wyszukuje za pomocą modelu programowania Map Reduce.
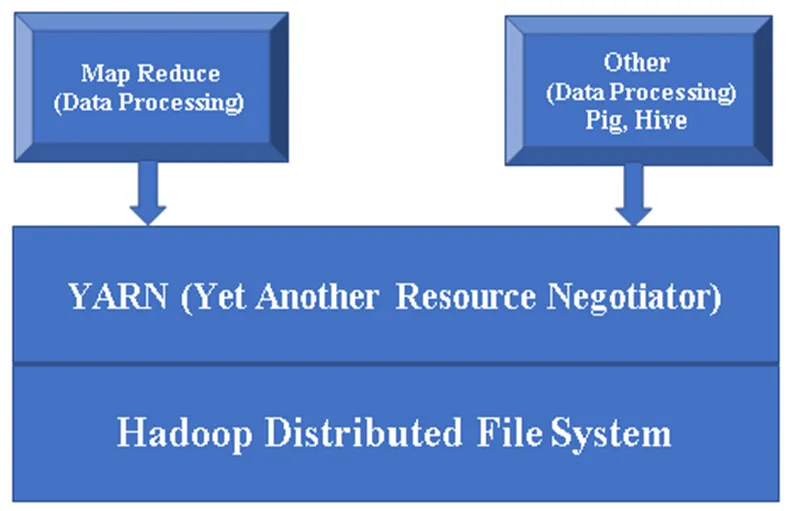
Rysunek 1, Podstawowa architektura komponentu Hadoop.
Główne komponenty Hadoop:
Hadoop Base / Common: Hadoop common zapewni jedną platformę do zainstalowania wszystkich swoich składników.
HDFS (Hadoop Distributed File System): HDFS jest główną częścią frameworka Hadoop, który dba o wszystkie dane w klastrze Hadoop. Działa na architekturze Master / Slave i przechowuje dane przy użyciu replikacji.
Architektura i replikacja Master / Slave:
- Węzeł główny / węzeł nazwy: węzeł nazwy przechowuje metadane każdego bloku / pliku przechowywanego w HDFS, HDFS może mieć tylko jeden węzeł główny (w przypadku HA inny węzeł główny będzie działał jako dodatkowy węzeł główny).
- Węzeł podrzędny / węzeł danych: Węzły danych zawierają rzeczywiste pliki danych w blokach. HDFS może mieć wiele węzłów danych.
- Replikacja: HDFS przechowuje swoje dane, dzieląc je na bloki. Domyślny rozmiar bloku to 64 MB. Ze względu na replikację dane są przechowywane w 3 (Domyślny współczynnik replikacji, można zwiększyć zgodnie z wymaganiami) różnych węzłów danych, dlatego istnieje najmniejsza szansa na utratę danych w przypadku awarii dowolnego węzła.
YARN (Yet Another Negotiator zasobów): Jest zasadniczo używany do zarządzania zasobami Hadoop, a także odgrywa ważną rolę w planowaniu aplikacji użytkowników.
MR (Map Reduce): Jest to podstawowy model programowania Hadoop. Służy do przetwarzania / przeszukiwania danych w ramach platformy Hadoop.
Ul:
Hive to aplikacja działająca w środowisku Hadoop i zapewniająca interfejs podobny do SQL do przetwarzania / wysyłania zapytań do danych. Hive został zaprojektowany i opracowany przez Facebooka, zanim stał się częścią projektu Apache-Hadoop.
Hive uruchamia swoje zapytanie przy użyciu HQL (język zapytań Hive). Hive ma taką samą strukturę jak RDBMS i prawie takie same polecenia mogą być używane w Hive.
Hive może przechowywać dane w zewnętrznych tabelach, więc nie jest obowiązkowy używany HDFS, a także obsługuje formaty plików takie jak ORC, pliki Avro, pliki sekwencji i pliki tekstowe itp.
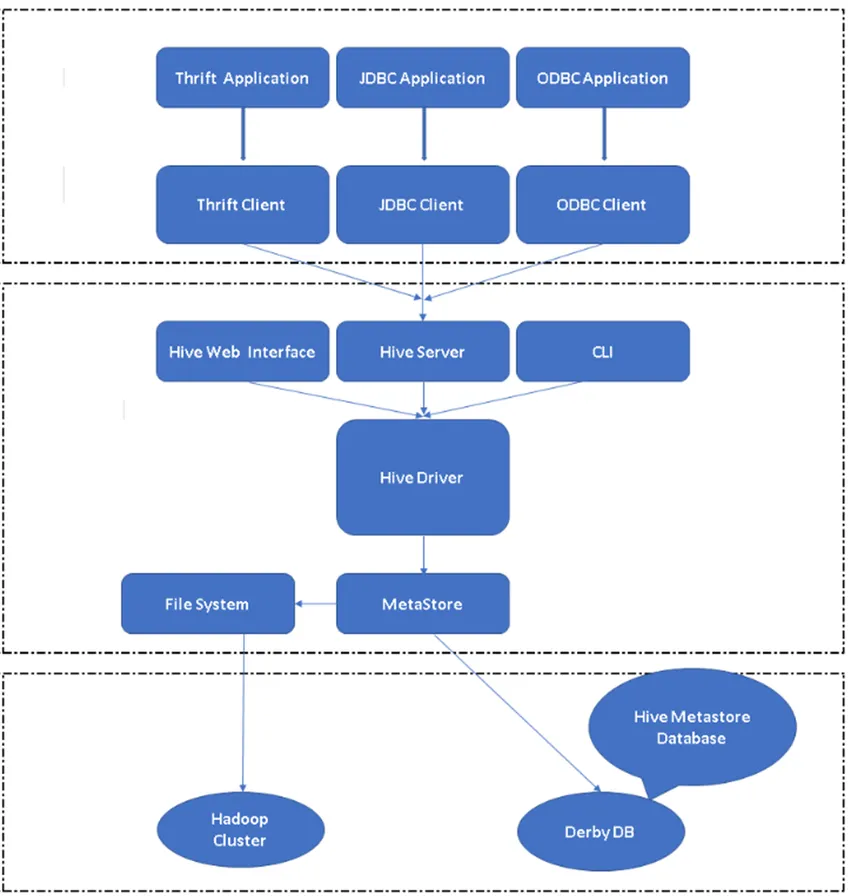
Ryc. 2, Architektura Hive i główne komponenty.
Główny składnik gałęzi:
Klienci Hive: nie tylko SQL, Hive obsługuje również języki programowania, takie jak Java, C, Python, używając różnych sterowników, takich jak ODBC, JDBC i Thrift. Można napisać dowolną aplikację kliencką w innych językach i uruchomić ją w Hive przy użyciu tych klientów.
Usługi Hive: w obszarze Usługi Hive odbywa się wykonywanie poleceń i zapytań. Interfejs sieciowy Hive ma pięć podskładników.
- CLI: domyślny interfejs wiersza poleceń udostępniany przez Hive do wykonywania zapytań / poleceń Hive.
- Interfejsy sieciowe Hive: Jest to prosty graficzny interfejs użytkownika. Jest alternatywą dla wiersza poleceń Hive i służy do uruchamiania zapytań i poleceń w aplikacji Hive.
- Serwer Hive: jest również nazywany oszczędnością Apache. Jest odpowiedzialny za pobieranie poleceń z różnych interfejsów linii poleceń i przesyłanie wszystkich poleceń / zapytań do Hive, a także pobiera ostateczny wynik.
- Sterownik Apache Hive: jest odpowiedzialny za pobieranie danych wejściowych z interfejsu CLI, interfejsu użytkownika sieci Web, interfejsów ODBC, JDBC lub Thrift przez klienta i przekazywanie tych informacji do magazynu danych, w którym przechowywane są wszystkie informacje o plikach.
- Metastore: Metastore to repozytorium do przechowywania wszystkich informacji metadanych Hive. Metadane Hive przechowują informacje, takie jak struktura tabel, partycje i typ kolumn itp.
Magazyn Hive: jest to miejsce, w którym wykonuje się rzeczywiste zadanie. Wszystkie zapytania uruchamiane z Hive wykonały akcję wewnątrz magazynu Hive.
Bezpośrednie porównanie Hadoop vs Hive (infografiki)
Poniżej znajduje się 8 najważniejszych różnic między Hadoop a Hive
Kluczowe różnice między Hadoop a Hive:
Poniżej znajdują się listy punktów, opisujące kluczowe różnice między Hadoop i Hive:
1) Hadoop to platforma do przetwarzania / wysyłania zapytań do dużych zbiorów danych, podczas gdy Hive jest narzędziem opartym na SQL, które opiera się na Hadoop do przetwarzania danych.
2) Przetwarzaj / wysyłaj zapytania do wszystkich danych za pomocą HQL (Hive Query Language) to język podobny do SQL, podczas gdy Hadoop może zrozumieć tylko Map Reduce.
3) Map Reduce jest integralną częścią Hadoop, zapytanie Hive jest najpierw konwertowane na Map Reduce, a następnie przetwarzane przez Hadoop w celu zapytania danych.
4) Hive działa na zapytaniu podobnym do SQL, podczas gdy Hadoop rozumie je, używając tylko mapy Reduce Map.
5) W Hive, wcześniej używane tradycyjne „Relacyjne bazy danych” mogą być również używane do wysyłania zapytań do dużych zbiorów danych, podczas gdy w Hadoop trzeba pisać skomplikowane programy Map Reduce przy użyciu Javy, która nie jest podobna do tradycyjnej Javy.
6) Hive może przetwarzać / sprawdzać dane strukturalne, podczas gdy Hadoop jest przeznaczony dla wszystkich typów danych, niezależnie od tego, czy są one ustrukturyzowane, nieustrukturyzowane, czy częściowo ustrukturyzowane.
7) Korzystając z Hive, można przetwarzać / przeszukiwać dane bez skomplikowanego programowania, podczas gdy w ekosystemie Simple Hadoop trzeba pisać złożony program Java dla tych samych danych.
8) Z jednej strony frameworki Hadoop potrzebują linii 100s do przygotowania programu MR opartego na Javie, z drugiej strony Hadoop z Hive może wysyłać zapytania do tych samych danych przy użyciu 8 do 10 linii HQL.
9) W Hive bardzo trudno jest wstawić dane wyjściowe jednego zapytania jako dane wejściowe innego, podczas gdy to samo zapytanie można łatwo wykonać za pomocą Hadoop z MR.
10) Nie jest obowiązkowe, aby Metastore był w klastrze Hadoop, podczas gdy Hadoop przechowuje wszystkie swoje metadane w HDFS (Hadoop Distributed File System).
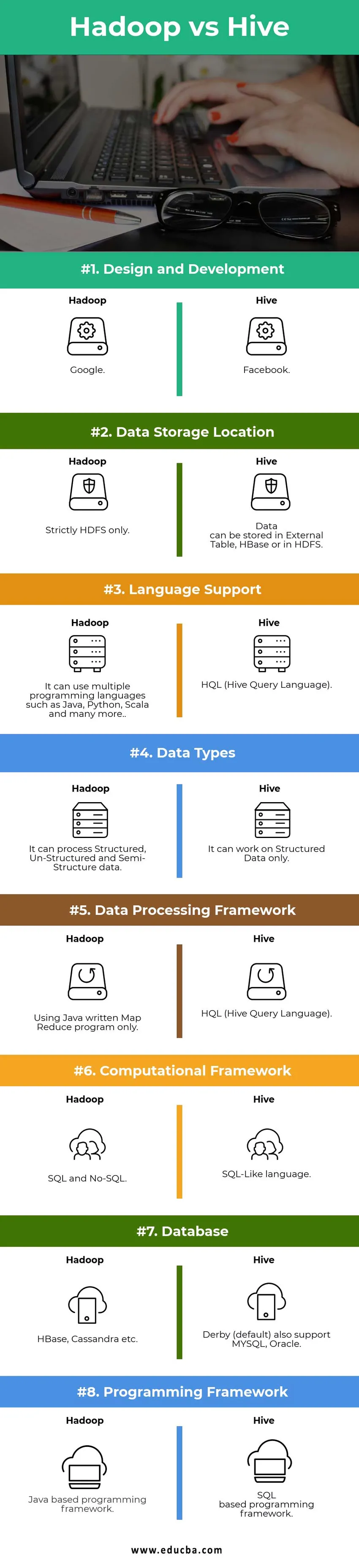
Tabela porównawcza Hadoop vs Hive
| Punkty porównania | Ul | Hadoop |
|
Projektowanie i rozwój | ||
| Miejsce przechowywania danych |
Dane mogą być przechowywane w Zewnętrznych Tabela, HBase lub w HDFS. | Ściśle tylko HDFS. |
| Wsparcie językowe | HQL (Hive Query Language) |
Może używać wielu języków programowania, takich jak Java, Python, Scala i wiele innych. |
| Typy danych | Może działać tylko na danych strukturalnych. |
Może przetwarzać dane strukturalne, niestrukturalne i półstrukturalne. |
| Ramy przetwarzania danych |
HQL (Hive Query Language) | Korzystanie wyłącznie z napisanego w języku Java programu Map Reduce. |
|
Ramy obliczeniowe | Język podobny do SQL. | SQL i bez SQL. |
| Baza danych |
Derby (domyślnie) obsługuje także MYSQL, Oracle… | HBase, Cassandra itp. |
| Ramy programowania |
Struktura programowania oparta na SQL. | Framework programistyczny oparty na Javie. |
Wniosek - Hadoop vs Hive
Hadoop i Hive są używane do przetwarzania dużych zbiorów danych. Hadoop to platforma, która zapewnia platformę dla innych aplikacji do wysyłania zapytań / przetwarzania Big Data, podczas gdy Hive jest tylko aplikacją opartą na SQL, która przetwarza dane za pomocą HQL (Hive Query Language)
Hadoop może być używany bez Hive do przetwarzania dużych zbiorów danych, podczas gdy nie jest łatwy w użyciu Hive bez Hadoop.
Podsumowując, nie możemy porównywać Hadoop i Hive w żaden sposób iw żadnym aspekcie. Zarówno Hadoop, jak i Hive są zupełnie inne. Wspólne korzystanie z obu technologii może znacznie ułatwić i przyspieszyć przetwarzanie zapytań Big Data dla użytkowników Big Data.
Polecane artykuły:
Jest to przewodnik po Hadoop vs Hive, ich znaczeniu, porównaniu bezpośrednim, kluczowych różnicach, tabeli porównawczej i wnioskach. Możesz także przejrzeć następujące artykuły, aby dowiedzieć się więcej -
- Hadoop vs Apache Spark - ciekawe rzeczy, które musisz wiedzieć
- HADOOP vs RDBMS | Poznaj 12 przydatnych różnic
- Jak duże zbiory danych zmieniają oblicze opieki zdrowotnej
- Top 12 Porównanie Apache Hive vs Apache HBase (infografiki)
- Niesamowity przewodnik na temat Hadoop vs Spark