

Różnice między Sqoop i Flume
Sqoop to produkt z oprogramowania Apache. Sqoop wyodrębnia przydatne informacje z Hadoop, a następnie przekazuje je do zewnętrznych magazynów danych. Za pomocą Sqoop możemy importować dane z RDBMS lub mainframe do HDFS. Flume pochodzi również z oprogramowania Apache. Gromadzi i przenosi generowane dane rekurencyjne. Flume Apache nie ogranicza się tylko do agregacji danych dziennika, ale źródła danych można dostosowywać, dzięki czemu Flume może być wykorzystywany do transportu ogromnych ilości danych. Najlepszym sposobem gromadzenia, agregowania i przenoszenia dużych ilości danych między rozproszonym systemem plików Hadoop a RDBMS jest użycie takich narzędzi, jak Sqoop lub Flume.
Omówmy te dwa najczęściej używane narzędzia do wyżej wspomnianego celu.
Co to jest Sqoop
Aby użyć Sqoop, użytkownik musi określić narzędzie, którego chce użyć użytkownik, oraz argumenty sterujące danym narzędziem. Możesz także wyeksportować dane z powrotem do RDBMS za pomocą Sqoop. Funkcja eksportu Sqoop służy do wydobywania przydatnych informacji z Hadoop i eksportowania ich do zewnętrznych strukturalnych magazynów danych. Działa z różnymi bazami danych, takimi jak Teradata, MySQL, Oracle, HSQLDB.
- Architektura Sqoop: -
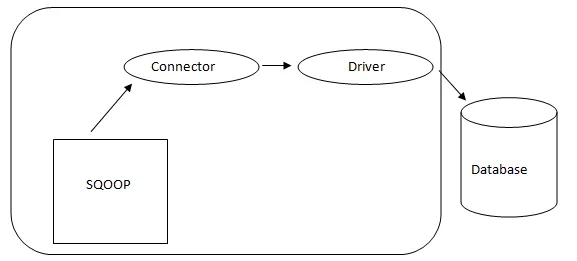
Architektura Sqoop
Łącznik w Sqoop jest wtyczką do określonego źródła bazy danych, więc fundamentalne jest, aby był to kawałek Sqoop. Pomimo faktu, że sterowniki są elementami specyficznymi dla bazy danych i dystrybuowanymi przez różnych dostawców baz danych, sam Sqoop jest dostarczany w pakiecie z różnymi typami łączników wykorzystywanych do powszechnego systemu baz danych i magazynowania informacji. Tak więc Sqoop jest dostarczany z różnorodnymi złączami po wyjęciu z pudełka. Sqoop zapewnia komponent wtykowy dla idealnej sieci i systemu zewnętrznego. Interfejs API Sqoop zapewnia przydatną strukturę do składania nowych łączników, dlatego też wszelkie łączniki bazy danych można upuścić do instalacji Sqoop, aby zapewnić łączność z różnymi systemami danych.
Co to jest Flume
Apache Flume nie ogranicza się tylko do agregacji danych dziennika, ale źródła danych można dostosowywać, dzięki czemu Flume może być używany do transportu ogromnych ilości danych, w tym między innymi wiadomości e-mail, danych generowanych przez media społecznościowe, danych o ruchu w sieci i praktycznie dowolnych możliwe źródło danych.
Architektura Flume: - Architektura Flume opiera się na wielu podstawowych koncepcjach:
- Flume Event - jest reprezentowany jako jednostka przepływających danych, która ma ładunek bajtowy i zestaw ciągów z opcjonalnymi nagłówkami ciągów. Flume uważa zdarzenie za zwykłą kroplę bajtów.
- Flume Agent - jest to proces JVM, który obsługuje komponenty, takie jak kanały, ujście i źródła. Może odbierać, przechowywać i przekazywać zdarzenia ze źródła zewnętrznego na wyższy poziom.
- Flume Flow - jest to moment, w którym generowane jest zdarzenie.
- Flume Client - odnosi się do interfejsu, w którym klient działa w punkcie początkowym zdarzenia i dostarcza go do agenta Flume.
- Źródło - źródło to takie, które zużywa zdarzenia o określonym formacie i dostarcza je za pośrednictwem określonego mechanizmu.
- Kanał - Jest to pasywny sklep, w którym wydarzenia odbywają się, dopóki zlew nie usunie go do dalszego transportu.
- Zlew - usuwa zdarzenie z kanału i umieszcza je w zewnętrznym repozytorium, takim jak HDFS. Obecnie obsługuje tworzenie plików tekstowych i sekwencji oraz obsługuje kompresję w obu typach plików.
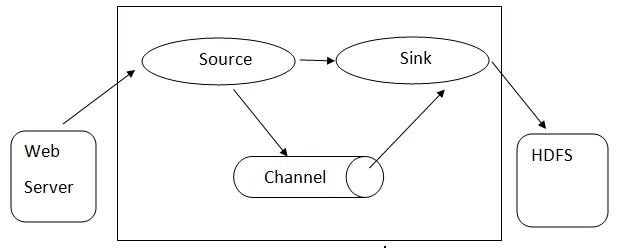
Architektura Flume
Bezpośrednie porównanie Sqoop vs Flume (infografiki)
Poniżej znajduje się porównanie 7 najlepszych między Sqoop vs Flume

Kluczowe różnice między Sqoop a Flume
Wiemy teraz, że istnieje wiele różnic między Sqoop a Flume, oto najważniejsze różnice między nimi podane poniżej -
1. Sqoop jest przeznaczony do wymiany masowej informacji między Hadoop a relacyjną bazą danych.
Natomiast Flume służy do gromadzenia danych z różnych źródeł, które generują dane dotyczące konkretnego przypadku użycia, a następnie przenoszą tak dużą ilość danych z zasobów rozproszonych do jednego scentralizowanego repozytorium.
2. Sqoop zawiera również zestaw poleceń, które pozwalają na sprawdzenie bazy danych, z którą pracujesz. Dlatego możemy rozważyć Sqoop jako zbiór powiązanych narzędzi.
Podczas zbierania daty Flume skaluje dane w poziomie, a wielu agentów Flume może działać, aby zbierać datę i agregować je. Następnie dzienniki danych są przenoszone do scentralizowanego magazynu danych, tj. Hadoop Distributed File System (HDFS).
3. Kluczowym czynnikiem przy korzystaniu z Flume jest to, że dane muszą być generowane w sposób ciągły i strumieniowy. Podobnie Sqoop najlepiej nadaje się w sytuacjach, gdy dane żyją w systemach baz danych, takich jak MySQL, Oracle, Teradata, PostgreSQL
Sqoop vs Flume (Tabela porównawcza)
| Podstawa do porównania | SQOOP | FLUME |
|
Podstawowa natura | Sqoop działa dobrze z każdym RDBMS, który ma JDBC (Java Database Connectivity), takim jak Oracle, MySQL, Teradata itp. | Flume działa dobrze w przypadku źródła strumieniowego przesyłania danych, które stale generuje, takie jak dzienniki, JMS, katalog, raporty o awariach itp. |
| Przepływ danych | Sqoop specjalnie używany do równoległego przesyłania danych. Z tego powodu dane wyjściowe mogą znajdować się w wielu plikach | Flume służy do gromadzenia i agregowania danych ze względu na ich rozproszony charakter. |
| Zdarzenia sterowane | Sqoop nie jest sterowany przez zdarzenia. | Flume jest całkowicie sterowany zdarzeniami. |
| Architektura | Sqoop działa zgodnie z architekturą opartą na złączach, co oznacza złącza, wie, jak połączyć się z innym źródłem danych. | Flume działa w oparciu o architekturę opartą na agencie, w której zapisany w nim kod jest znany jako agent odpowiedzialny za pobieranie danych. |
| Gdzie używać | Używany głównie do szybszego kopiowania danych, a następnie do generowania wyników analitycznych. | Zwykle służy do pobierania danych, gdy firmy chcą analizować wzorce, przyczyny pierwotne lub analizę nastrojów za pomocą dzienników i mediów społecznościowych. |
| Występ | Redukuje nadmierne obciążenia związane z przechowywaniem i przetwarzaniem, przenosząc je do innych systemów i ma wysoką wydajność. | Flume jest odporny na uszkodzenia, solidny i ma trwały mechanizm niezawodności do przełączania awaryjnego i odzyskiwania. |
| Historia wydań | Pierwsza wersja Apache Sqoop została wydana w marcu 2012 roku. Obecna stabilna wersja to 1.4.7 | Pierwsza stabilna wersja Apache Flume 1.2.0 została wydana w czerwcu 2012 r. Obecna stabilna wersja to Apache Flume wersja 1.8.0. |
Wniosek - Sqoop vs Flume
Jak dowiedziałeś się powyżej Sqoop i Flume, przede wszystkim używa się dwóch narzędzi do przetwarzania danych w świecie Big Data. Jeśli musisz zaimportować tekstowe dane dziennika do Hadoop / HDFS, Flume jest właściwym wyborem. Jeśli Twoje dane nie są regularnie generowane, Flume nadal będzie działać, ale będzie to przesada w tej sytuacji. Podobnie Sqoop nie nadaje się najlepiej do obsługi danych sterowanych zdarzeniami.
Polecane artykuły
Był to przewodnik po różnicach między Sqoop a Flume, ich znaczeniu, porównaniu bezpośrednim, kluczowych różnicach, tabeli porównawczej i wnioskach. ten artykuł zawiera wszystkie przydatne różnice między Sqoop i Flume. Możesz także przejrzeć poniższe artykuły, aby dowiedzieć się więcej
- Hadoop vs Teradata - Przydatne różnice do nauczenia się
- 5 Najważniejsza różnica między Apache Kafka a Flume
- Big Data vs Apache Hadoop - porównanie 4 najlepszych wyników
- 5 Najważniejsza różnica między Apache Kafka a Flume
- Ważne wyszukiwanie tekstu a przetwarzanie języka naturalnego - 5 najlepszych porównań