

Wprowadzenie do architektury Hadoop
Architektura Hadoop jest strukturą open source, która pomaga w łatwym przetwarzaniu dużych zbiorów danych. Pomaga w tworzeniu aplikacji, które przetwarzają ogromne dane z większą prędkością. Wykorzystuje koncepcje przetwarzania rozproszonego, w których dane są rozproszone po różnych węzłach klastra. Aplikacje zbudowane przy użyciu Hadoop korzystają z komputerów towarowych. Komputery te są łatwo dostępne na rynku po niskich stawkach. Rezultatem jest uzyskanie większej mocy obliczeniowej przy niskim koszcie. Wszystkie dane obecne w Hadoop znajdują się w HDFS zamiast w lokalnym systemie plików. HDFS to rozproszony system plików Hadoop. Model ten oparty jest na lokalizacji danych, w której logika obliczeniowa jest wysyłana do węzłów obecnych w klastrze zawierającym dane. Ta logika jest niczym innym, jak logiką, która kompiluje program.
Architektura Hadoop
Podstawową ideą tej architektury jest to, że całe przechowywanie i przetwarzanie odbywa się w dwóch etapach i na dwa sposoby. Pierwszym krokiem jest przetwarzanie, które wykonuje program Map redukuj, a drugim krokiem jest przechowywanie danych, które są wykonywane na HDFS. Ma architekturę master-slave do przechowywania i przetwarzania danych. Węzłem głównym do przechowywania danych w Hadoop jest węzeł nazwy. Istnieje również węzeł główny, który wykonuje monitorowanie i równolegle przetwarza dane, wykorzystując Hadoop Map Reduce. Urządzenia podrzędne to inne maszyny w klastrze Hadoop, które pomagają w przechowywaniu danych, a także wykonują złożone obliczenia. Każdy węzeł podrzędny ma przypisany moduł do śledzenia zadań, a węzeł danych ma moduł do śledzenia zadań, który pomaga w uruchamianiu procesów i ich skutecznej synchronizacji. Ten typ systemu można skonfigurować w chmurze lub lokalnie. Węzeł Nazwa jest pojedynczym punktem awarii, gdy nie działa w trybie wysokiej dostępności. Architektura Hadoop ma również możliwość utrzymywania węzła Stand by Name w celu zabezpieczenia systemu przed awariami. Wcześniej istniały drugorzędne węzły nazw, które działały jako kopia zapasowa, gdy główny węzeł nazw był wyłączony.
FSimage and Edit Log
FSimage i Edytuj dziennik zapewniają trwałość metadanych systemu plików, aby nadążyć za wszystkimi informacjami, a węzeł nazwy przechowuje metadane w dwóch plikach. Te pliki to FSimage i dziennik edycji. Zadaniem FSimage jest utrzymywanie pełnej migawki systemu plików w danym momencie. Zmiany, które są ciągle wprowadzane w systemie, muszą być rejestrowane. Te przyrostowe zmiany, takie jak zmiana nazwy lub dołączanie szczegółów do pliku, są zapisywane w dzienniku edycji. Framework zapewnia lepszą opcję niż tworzenie nowego FSimage za każdym razem, lepszą opcją jest przechowywanie danych podczas tworzenia nowego pliku dla FSimage. FSimage tworzy nową migawkę za każdym razem, gdy wprowadzane są zmiany. Jeśli węzeł Nazwa ulegnie awarii, może przywrócić poprzedni stan. Drugorzędny węzeł nazwy może również aktualizować swoją kopię, ilekroć pojawią się zmiany w FSimage i dzienniki edycji. W ten sposób zapewnia, że nawet jeśli węzeł nazwy jest wyłączony, w obecności wtórnego węzła nazwy nie nastąpi utrata danych. Węzeł nazw nie wymaga ponownego ładowania tych obrazów do dodatkowego węzła nazw.
Replikacja danych
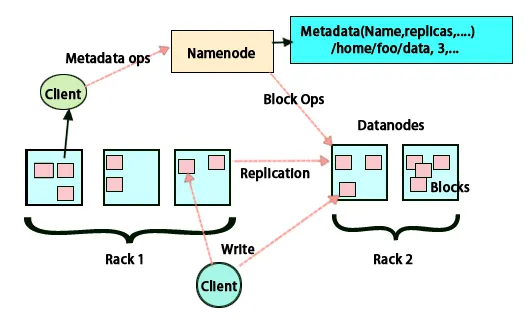
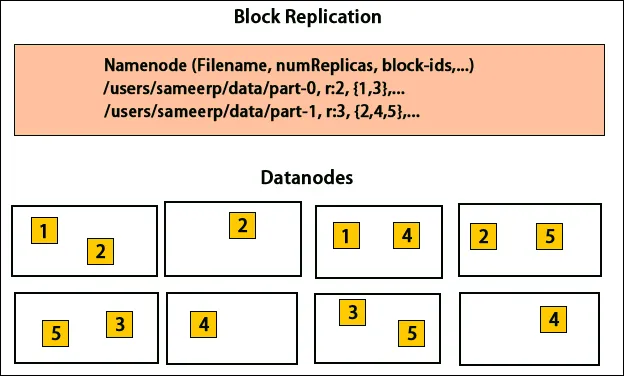
HDFS jest zaprojektowany do szybkiego przetwarzania danych i dostarczania wiarygodnych danych. Przechowuje dane na różnych komputerach i w dużych klastrach. Wszystkie pliki są przechowywane w szeregu bloków. Bloki te są replikowane w celu zapewnienia odporności na uszkodzenia. Rozmiar bloku i współczynnik replikacji mogą być ustalane przez użytkowników i konfigurowane zgodnie z wymaganiami użytkownika. Domyślnie współczynnik replikacji wynosi 3. Współczynnik replikacji można określić w momencie tworzenia pliku i można go zmienić później. Wszystkie decyzje dotyczące tych replik są podejmowane przez węzeł nazwy. Węzeł nazwy ciągle wysyła bicie serca i raport blokowy w regularnych odstępach czasu dla wszystkich węzłów danych w klastrze. Otrzymanie pulsu oznacza, że węzeł danych działa poprawnie. Raport bloków określa listę wszystkich bloków obecnych w węźle danych.
Umieszczenie replik
Umieszczenie replik jest bardzo ważnym zadaniem w Hadoop dla niezawodności i wydajności. Wszystkie różne bloki danych są umieszczone na różnych stojakach. Implementacja umieszczania repliki może odbywać się według niezawodności, dostępności i wykorzystania przepustowości sieci. Klaster komputerów można rozłożyć na różne szafy. Na tym samym stelażu można umieścić nie więcej niż dwa węzły. Trzecią replikę należy umieścić na innym stojaku, aby zapewnić większą niezawodność danych. Dwa węzły w szafie komunikują się za pośrednictwem różnych przełączników. Nazwa węzła ma identyfikator szafy dla każdego węzła danych. Ale umieszczenie wszystkich węzłów na różnych stelażach zapobiega utracie jakichkolwiek danych i umożliwia wykorzystanie przepustowości z wielu stelaży. Ogranicza także ruch między szafami i poprawia wydajność. Ponadto prawdopodobieństwo awarii szafy jest bardzo mniejsze w porównaniu z awarią węzła. Zmniejsza łączną przepustowość sieci, gdy dane są odczytywane z dwóch unikalnych stojaków, a nie z trzech.
Zmniejsz mapę
Map Reduce służy do przetwarzania danych przechowywanych na HDFS. Zapisuje rozproszone dane w rozproszonych aplikacjach, co zapewnia wydajne przetwarzanie dużych ilości danych. Przetwarzają na dużych klastrach i wymagają towaru, który jest niezawodny i odporny na uszkodzenia. Rdzeniem programu Map-reduk mogą być trzy operacje, takie jak mapowanie, zbieranie par i tasowanie danych wynikowych.
Wniosek - architektura Hadoop
Hadoop to platforma typu open source, która pomaga w systemie odpornym na uszkodzenia. Może przechowywać duże ilości danych i pomaga w przechowywaniu wiarygodnych danych. Dwie części przechowywania danych w HDFS i przetwarzania ich poprzez mapowanie zmniejszają pomoc w prawidłowym i wydajnym działaniu. Ma architekturę, która pomaga w zarządzaniu wszystkimi blokami danych, a także w posiadaniu najnowszej kopii poprzez przechowywanie jej w FSimage i edytowanie dzienników. Współczynnik replikacji pomaga również mieć kopie danych i odzyskiwać je w przypadku awarii. HDFS przenosi również usunięte pliki do katalogu kosza w celu optymalnego wykorzystania miejsca.
Polecane artykuły
To był przewodnik po architekturze Hadoop. Omówiliśmy tutaj architekturę, redukcję map, rozmieszczenie replik, replikację danych. Możesz także przejrzeć nasze inne sugerowane artykuły, aby dowiedzieć się więcej -
- Zostań programistą Hadoop
- Wprowadzenie do Androida
- Co to jest Tableau? | Przegląd
- Co to jest MapReduce w Hadoop?